Responsible AI on AWS: What the AIF-C01 Exam Expects You to Know
April 06, 2026

Domain 4 of the AWS AI Practitioner exam covers Responsible AI and accounts for 14% of your score. It splits into two task statements: explaining how to develop responsible AI systems (4.1), and recognizing why model transparency and explainability matter (4.2). Together they form a coherent set of concepts around how to build, audit, and govern AI systems that treat people fairly.
This post covers the core concepts, the AWS tools, and the exam-level distinctions you need sharp before test day.
The Six Dimensions of Responsible AI
AWS frames responsible AI around six dimensions. These appear throughout the exam in different combinations.
Fairness means models treat everyone equitably regardless of age, location, gender, or ethnicity. Fairness is measured through bias and variance metrics across demographic groups.
Explainability is the ability to describe in human terms why a model produced a specific output. Why was this loan rejected? Explainability does not require understanding the model's internals.
Robustness means the system tolerates failures and minimizes error rates across inputs.
Privacy and security means protecting user data and avoiding exposure of personally identifiable information (PII) through model outputs.
Governance covers compliance with industry standards, risk estimation, and regular audits of AI systems.
Transparency means communicating clearly about what a model can and cannot do. Users should know when they are interacting with AI.
Bias in Training Data: The Root Cause
The primary driver of biased model outputs is class imbalance in training data -- when one feature value has far fewer samples than another. A model trained on a dataset that is 67.6% male and 32.4% female will perform better for men. For women, it may overfit due to undersampling, producing higher error rates. If that model predicts disease diagnoses, the real-world consequence is women being misdiagnosed at a higher rate.
Responsible datasets need to be inclusive, balanced, regularly audited, privacy-respecting, and built with informed consent from data subjects. Responsible model selection also factors in environmental impact: reuse pre-trained models when possible to reduce compute costs and carbon footprint.
SageMaker Clarify: Bias Detection Before and After Training
Amazon SageMaker Clarify is the primary AWS tool for bias detection and explainability. It runs as a processing job that treats the model as a black box, observing inputs and outputs without needing access to model weights. This means it works on deep learning, computer vision, and NLP models alike.
Clarify detects bias at three points: during data preparation, after model training, and in the deployed model.
Dataset bias metrics:
Class imbalance: More records for one class than another
Label imbalance: Labels favor positive outcomes for one class (e.g., loans approved at higher rates for middle-aged applicants)
Demographic disparity: One class has a disproportionate share of negative outcomes
Trained model bias metrics:
Recall difference: Gap in true positive rate between classes
Accuracy difference: Different prediction accuracy across classes, often caused by training data imbalance
Treatment equality: Difference in the ratio of false negatives to false positives between classes -- same overall accuracy but unequal error types across groups
Specificity difference: How often the model correctly predicts a negative outcome per class
Key exam distinction: bias can exist in the data before training OR be introduced during training. Clarify gives you metrics to detect both.
GenAI-Specific Risks
Generative AI introduces risks that traditional ML does not surface at the same scale.
Hallucination: The model generates content that sounds factual but is fabricated. In 2023, lawyers submitted a legal brief with AI-generated case citations to a New York court. The cases were fake, the case was dismissed, and the lawyers were sanctioned.
IP and copyright: AI-generated works cannot be copyrighted. A model may have been trained on copyrighted data that surfaces in outputs. Getty Images sued Stable Diffusion's creators for allegedly using 12 million photos without authorization.
Bias and discrimination: Biased outputs create legal liability. The EEOC sued companies for using an AI hiring tool that automatically rejected female applicants over 55 and male applicants over 60.
Toxic content: Models can generate harmful content if it existed in training data.
Data privacy: Sensitive data in training or prompts can leak through outputs. Once a foundation model is trained on data, deleting the source does not make it forget.
Amazon Bedrock Guardrails: Filtering at the API Layer
Amazon Bedrock Guardrails lets you filter and block inappropriate content at the model level. You configure thresholds for content categories (hate, insults, sexual content, violence) and topic blocks using plain text descriptions of topics that should always be denied.
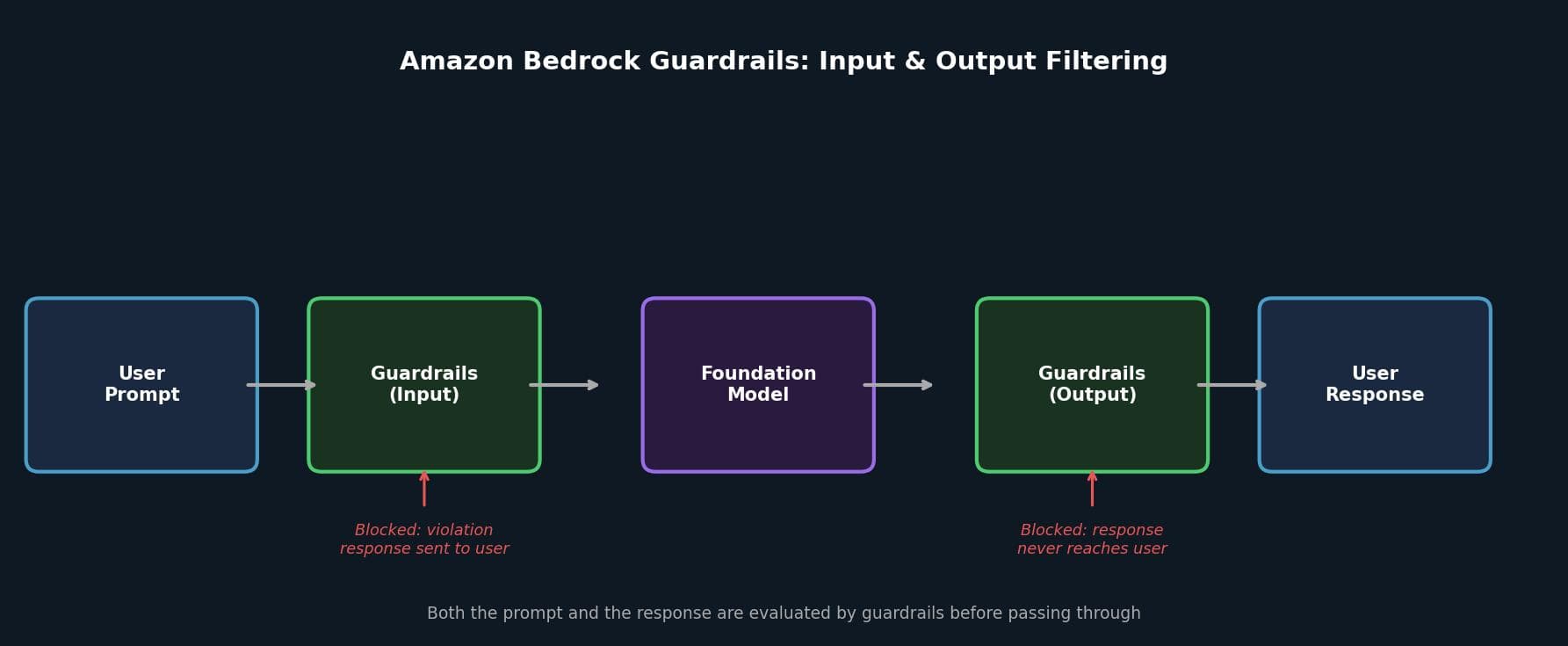
Filtering runs in both directions: the prompt is evaluated before reaching the model, and the response is evaluated before reaching the user. If either is blocked, the model never sees the prompt or the user never sees the response.
SageMaker Clarify also supports LLM evaluation jobs to benchmark foundation models across five dimensions: prompt stereotyping, toxicity, factual knowledge, semantic robustness, and accuracy. The same capabilities are available in the Amazon Bedrock console.
Interpretability vs. Explainability
Transparency in AI has two distinct measures the exam treats as separate concepts.
Interpretability is understanding how a model works internally. Linear regression has high interpretability (visible slope and intercept). Decision trees produce readable rules. Neural networks have low interpretability: you understand that signals propagate through billions of neurons, but cannot trace how that produces a specific output.
Explainability is describing what a model is doing without knowing exactly how. It treats the model as a black box and uses model-agnostic approaches to answer questions like "why was this loan rejected?" It works on any model, regardless of complexity.
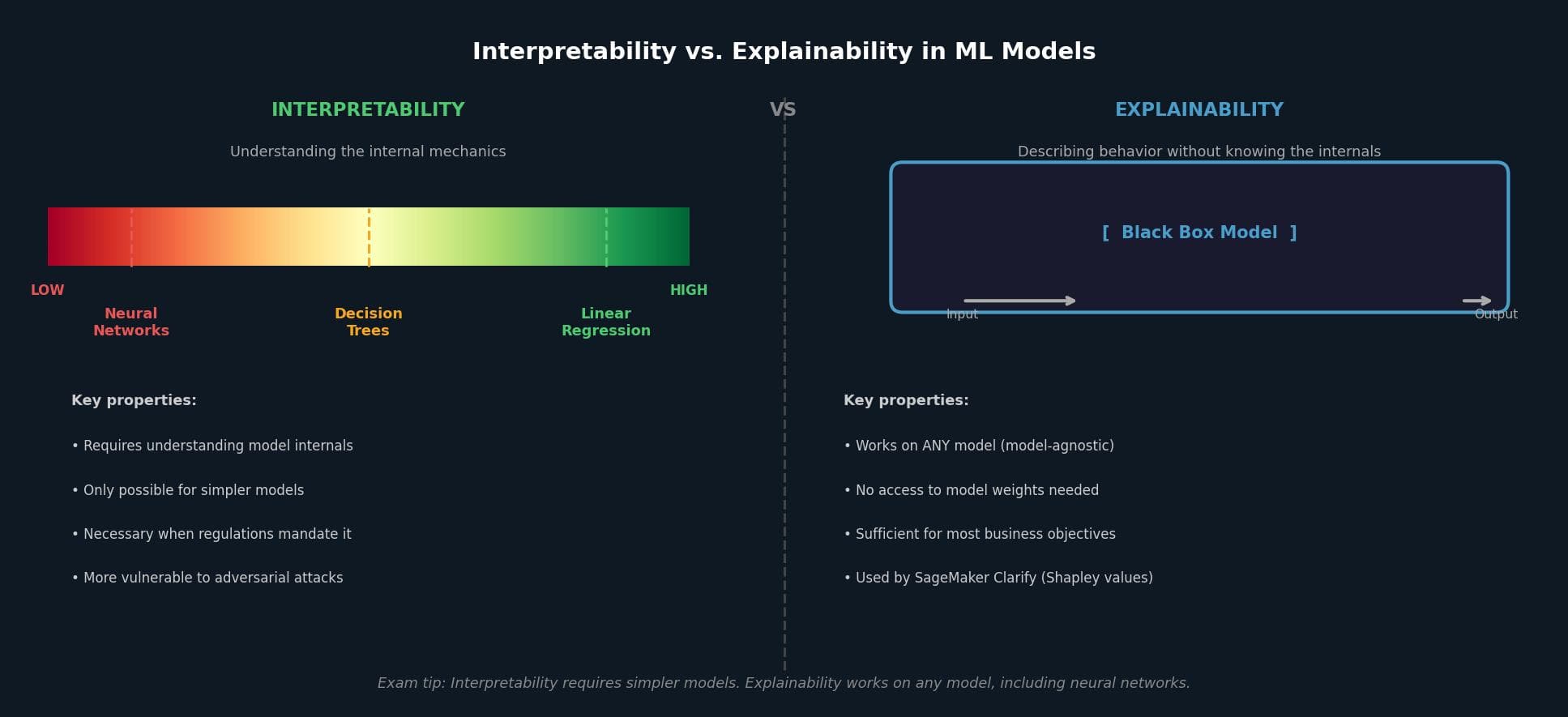
The tradeoffs are real. Interpretable models perform worse. A translation model using simple lookup rules is interpretable, but a neural network produces far better output. Transparent models are also more vulnerable to attack: when an attacker understands a model's mechanics, they can find exploits. If regulations require full transparency, you must select an interpretable model upfront. For most business objectives, explainability is sufficient.
AWS Tools for Documenting Transparency
When you use a model hosted by AWS via API, you have no access to its internals. AWS addresses this through AI Service Cards -- documentation covering intended use cases, limitations, responsible AI design choices, and optimization best practices. Cards currently exist for Amazon Rekognition, Amazon Textract, Amazon Comprehend, and Amazon Titan Text.
For models you train yourself, Amazon SageMaker Model Cards document the full lifecycle. SageMaker autopopulates details for SageMaker-trained models, including training datasets and containers used.
SageMaker Clarify reports explainability through Shapley values, which rank each feature's contribution to model predictions. The output is a bar chart showing which features had the most impact. Clarify also supports partial dependence plots (PDPs), showing how predictions change across different values of a specific feature.
Human-Centered AI: Amazon A2I and RLHF
Amazon Augmented AI (Amazon A2I) incorporates human review into AI inference workflows. You configure it to send low-confidence inferences to human reviewers before delivering results, or to send random predictions for auditing. Reviewers can come from your organization or Amazon Mechanical Turk. Human feedback from A2I can be added to training data to retrain and improve the model.
Reinforcement Learning from Human Feedback (RLHF) is the standard technique for aligning LLM outputs with human values -- making them more truthful, harmless, and helpful. The LLM generates multiple responses to the same prompt; human reviewers rank them by preference; these rankings train a separate reward model; and the LLM is then fine-tuned to maximize its predicted human preference score.
Amazon SageMaker Ground Truth is the AWS tool for collecting human preferences for RLHF. Workers are presented with multiple model responses and asked to rank them.
Practical Takeaways for the Exam
A few distinctions that come up repeatedly in Domain 4 questions:
Bias can exist before training (dataset level) or be introduced during training. Know which Clarify metrics apply to each: class imbalance, label imbalance, and demographic disparity for datasets; recall difference, accuracy difference, treatment equality, and specificity difference for trained models.
Interpretability and explainability are not the same. Interpretability requires understanding model internals and only works for simpler models. Explainability uses black-box observation and works on any model.
Bedrock Guardrails filters in both directions. If a question describes harmful model output reaching a user, Guardrails is the answer.
Amazon A2I routes low-confidence inferences to human reviewers at inference time. RLHF incorporates human preferences into the training process. Different intervention points.
AI Service Cards are for AWS-managed models. SageMaker Model Cards are for models you train yourself.