Sixteen spec documents before I scaffolded a single screen
May 29, 2026

Discovery was done. I had a document full of pain points, workflows, and design notes pulled out of five-year-old interviews and a spreadsheet that runs a friend's entire therapy practice. The obvious next move, the one every instinct I have points at, was to open a code editor and start building screens.
I didn't. I opened a blank document instead. By the time I stopped there were sixteen of them, and I still hadn't written a line of production code.
The urge to start building
I want to be honest about how strong that urge is. Building screens is the part of this work I am good at and the part I enjoy. Discovery had handed me a clear enough picture that I could have scaffolded a project, stood up a few routes, and had something clickable by the end of the week. That would have felt like progress.
The problem is that code makes decisions whether you mean it to or not. Every default value, every required field, every "this links to that" is a product decision. When you make those decisions in code first, you make most of them by accident, in passing, while you are thinking about something else. They harden into the implementation, and nobody ever wrote them down or argued about whether they were right.
A spec is where you make those decisions on purpose, before they get baked in. So instead of building, I wrote.
What I wrote instead
The set came out to eight kinds of document. A domain model: the entities, how they relate, and how the messy spreadsheet maps onto clean tables. A catalog of thirty-five user stories, each one prioritized for what the first version needs and what can wait. Six workflow diagrams covering the two dozen workflows I had pulled out of discovery. A UI requirements doc covering twelve screens. A non-functionals doc for performance, migration, security, and language. A story map. A release plan. Effort estimates.
Counting each workflow diagram as its own file, plus the planning docs for the validation round that came right after, the specs folder held sixteen markdown files before I scaffolded a single screen. Around forty thousand words. Zero production code.
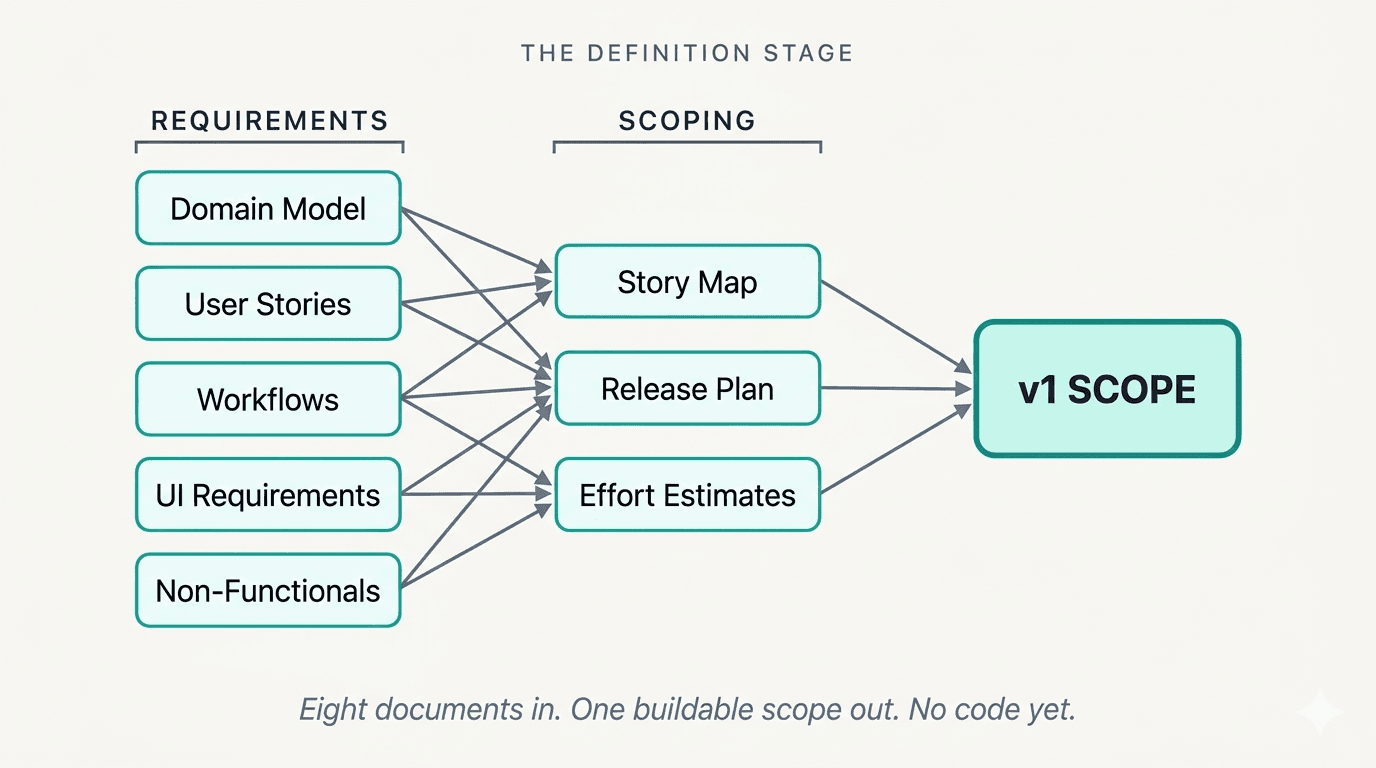
I drafted all of it in conversation with Claude, with the insights document open the whole time as the source of truth. The rule I held to was simple. Every user story has to trace back to a specific pain point, and every pain point traces back to a specific quote from one of the interviews. The agent was good at holding that chain honest. When I tried to add a story because it seemed obviously useful, the first question was which pain point it traced to, and more than once the honest answer was "none, I just assumed it." That is exactly the kind of thing you want to catch in a document, not in a shipped feature.
The decisions the spec forced
Two examples of what writing it down caught.
The first is couples. She sees patients individually and as couples, and in her spreadsheet a couple was entered as two names in one cell, the partner's name in parentheses. If I had gone straight to code I would have built a patient record as one row, one person, and discovered the problem the day I tried to register a couple's session. Modeling it on paper forced the real question early: a couple is two patient records plus a relationship between them, and a shared session has to attribute payments and invoices correctly across both people. That is a decision worth making slowly, before any of it is load-bearing.
The second is invoicing. The person an invoice is billed to is often not the patient. A parent pays for a teenager. A relative pays for someone living abroad. If I had assumed "the invoice goes to the patient," which is the obvious assumption, I would have hard-coded it and torn it out later. Writing the spec made me notice that the person being treated and the person being billed are two different fields, and that the app has to ask whose name the invoice goes in. I only know that because she mentioned it three years ago, and the synthesis pass over the interviews surfaced it. The spec is where it became a column instead of a surprise.
Neither of these is a hard engineering problem. Both are cheap to handle if you know about them before you build, and expensive to retrofit after. The spec is where you find out.
What the specs became
Here is the part I did not expect when I started.
Those sixteen documents were not the finished product. They were the starting point for six weeks of validation, where I sat with the actual user and walked her through prototypes built from them. And validation kept writing back into the specs. Every session produced amendments: a label that did not read clearly, a workflow that did not match how she actually works, a feature she asked for that I had not modeled. The spec set has more than tripled since I "finished" it. It is past a hundred thousand words now, and almost none of that growth is me sitting alone writing. It is the documents absorbing what the user taught me.
That changed how I think about what a spec is. I used to treat one as a deliverable: a thing you produce, approve, and file. This one behaves more like a source of truth the whole project keeps reading from and writing to. The code, when I get to it, will be downstream of this. The specs are the thing that stays.
I will say the obvious calibration out loud. Sixteen documents and forty thousand words, growing past a hundred thousand, is the upper bound, not the floor. This project has five years of historical data to honor and no commercial deadline, so I have room to be this thorough. For a normal startup MVP I would compress the same shape into a handful of documents written in a few days. The point is not the word count. The point is that the decisions get made explicitly, somewhere you can see them, before code makes them for you.
The building already happened
The thing I keep noticing is that the building already happened. Not the typing; the building. The hard calls about what this app is, what it stores, how a couple works, who an invoice belongs to, what makes the first version and what waits, all of that is decided and written down. When I finally open the code editor, I will be transcribing decisions that already exist, not making them. The code is going to be the fast part.
I am not saying that to sound clever about process. I am saying it because it genuinely surprised me, and it keeps being true at every phase. The work moved to the part before the code, and the spec is where I can see it most clearly.
#BuildInPublic #ClaudeCode #AIEngineering #AIAgenticEngineer