Practical AI Use Cases, ML Problem Types, and AWS Pre-Trained Services for the AIF-C01 Exam
March 30, 2026

Task Statement 1.2 of the AWS AI Practitioner exam (AIF-C01) is about knowing when to use AI, which ML approach fits each problem, and which AWS services already solve common use cases out of the box. This post covers the full scope: when AI is the right call (and when it is not), how to match dataset characteristics to problem types, the five AWS pre-trained AI services you need to know, and real-world case studies that tie it all together.
When AI Should Be Used
AI excels at tasks that are repetitive, data-intensive, or require pattern recognition at scale. It can work all day without decreasing performance. It is ideal for analyzing vast amounts of data at high velocity, recognizing patterns, detecting deviations, uncovering fraud, and forecasting demand. The result: companies make better decisions, operate more efficiently, and serve customers better.
When AI is NOT the Best Option
Not every problem needs AI. The exam tests three specific scenarios where AI is the wrong choice.
Cost Exceeds Benefit. Training AI consumes vast resources and processing power can be costly. Models may need frequent re-training. Before starting an AI project, confirm that business benefits outweigh the cost. Example: estimate fraud reduction savings in dollar amounts, compare against model build cost, and only proceed if savings exceed costs.
Interpretability Requirements. Complex neural networks simulate the human brain, but you cannot fully understand how their inner mechanics impact a prediction. This is known as model interpretability. Complex models present a tradeoff: complexity vs. interpretability. If business or compliance requirements demand complete transparency, less complex models must be used, which typically results in lower performance. The alternative: use a rule-based system that does not require AI. Example: anyone with a credit score above 750 is automatically approved for a loan of $10,000 or less.
Determinism is Required. Deterministic systems always produce the same output for the same input. Rule-based applications are deterministic. ML models are probabilistic; they determine the likelihood of something and incorporate randomness, meaning identical inputs can produce varied outputs. If consistent, repeatable outputs are required, a rule-based system is the better option.
ML Problem Types: How to Identify the Right Approach
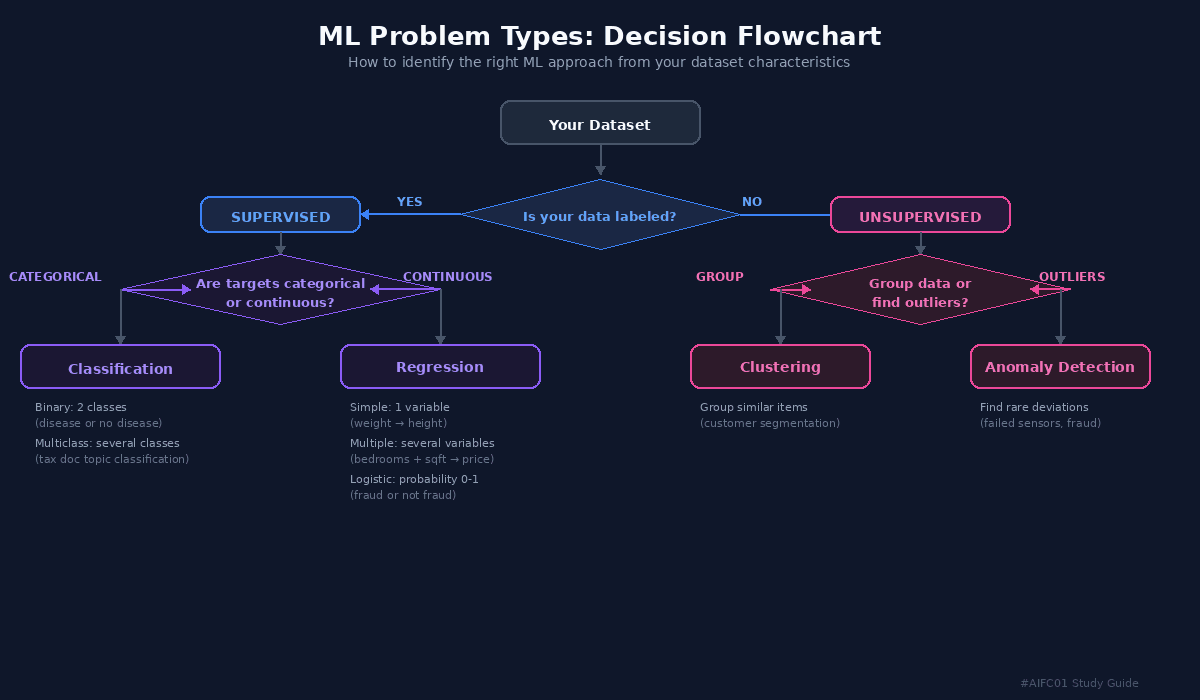
The exam will give you a dataset scenario and expect you to identify the correct ML problem type. The decision starts with one question: is your data labeled?
ML Problem Types Decision Flowchart showing the path from dataset characteristics to the correct ML approach
Supervised Learning (Labeled Data)
If your data has features with labeled target values, it is a supervised learning problem. From there, you check the nature of the target values.
Classification applies when target values are categorical (discrete). Binary classification assigns input to one of two mutually exclusive classes, like a medical diagnosis: disease or no disease. Multiclass classification assigns input to one of several classes, like predicting the topic most relevant to a tax document.
Regression applies when target values are mathematically continuous. Simple linear regression uses a single independent variable (predicting height from weight). Multiple linear regression uses several variables (predicting house price from bedrooms, square footage, and garden size). Logistic regression measures the probability of an event occurring, outputting a value between 0 and 1. Example: predicting whether a financial transaction is fraud. Both logistic and linear regression require significant labeled data to become accurate.
Unsupervised Learning (Unlabeled Data)
If your data has features but no labels or target values, it is an unsupervised learning problem.
Clustering classifies data into groups where members within a group are as similar as possible and as different as possible from other groups. Example: segmenting customers by purchase history.
Anomaly Detection identifies rare items, events, or observations that differ significantly from the rest of the data. Example: detecting failed sensors or medical errors.
AWS Pre-Trained AI Services
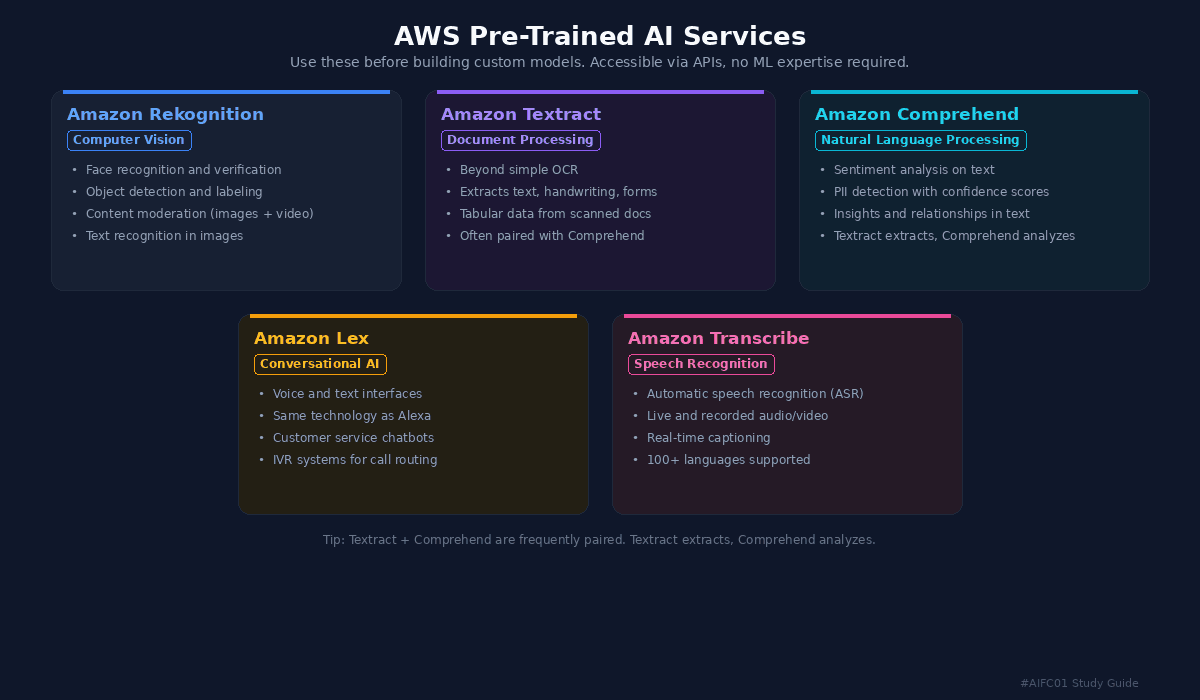
For many common use cases, it is not necessary to build and train a custom model. AWS offers pre-trained AI services accessible through APIs. Before investing effort in a custom model, investigate whether an existing service covers the use case.
AWS Pre-Trained AI Services reference card showing Rekognition, Textract, Comprehend, Lex, and Transcribe
Amazon Rekognition is a pre-trained deep learning service for computer vision. It works with images, videos, and streaming video. Capabilities include face recognition and verification, object detection and labeling, custom object recognition, text recognition in images, and content moderation for filtering explicit or inappropriate content.
Amazon Textract goes beyond simple optical character recognition (OCR). It extracts text, handwriting, forms, and tabular data from scanned documents.
Amazon Comprehend is a natural language processing (NLP) service that discovers insights and relationships in text. Key use cases: sentiment analysis (classifying customer feedback) and PII detection (finding personally identifiable information with confidence scores). A practical application: set a confidence threshold to automatically remove PII from ML training data.
Amazon Lex helps build voice and text interfaces using the same technology that powers Amazon Alexa. Common use cases include customer service chatbots and interactive voice response (IVR) systems for call routing.
Amazon Transcribe is an automatic speech recognition (ASR) service supporting over 100 languages. It processes live and recorded audio or video and produces transcriptions for search and analysis. Common use case: captioning streaming audio in real time.
Textract and Comprehend are frequently used together: Textract extracts content from documents, then Comprehend performs sentiment analysis or PII detection on that content.
Real-World Case Studies
The final lesson grounds these concepts in five production systems.
MasterCard trained a fraud detection model using Amazon SageMaker that tripled detected fraudulent transactions and reduced false positives by a factor of 10. In 2024, they added generative AI to improve detection by 20% on average by using an LLM to analyze a customer's transaction history and predict whether a business is a place the customer would likely visit.
DoorDash replaced an outdated touch-tone IVR system with Amazon Lex and NLP, letting customers speak instead of pressing buttons. Result: improved experience, decreased hold times, and increased self-service adoption.
Laredo Petroleum operates over 1,300 oil and gas wells in west Texas. They built a data streaming solution on AWS with Amazon SageMaker models to monitor pressure, temperature, and flow rate sensors in real time. The system proactively identifies maintenance needs and detects leaks in storage tanks.
Booking.com manages over 150 petabytes of data across 28 million accommodation listings. Their AI Trip Planner uses generative AI to engage customers in natural language, then calls the booking recommendation API and retrieves customer reviews to make suggestions. This is a direct example of Retrieval Augmented Generation (RAG) in production.
Pinterest uses computer vision for Pinterest Lens, where users photograph an object and immediately see similar items for sale. They maintain billions of labeled product images in Amazon S3 and label data using Amazon Mechanical Turk and Amazon SageMaker Ground Truth.