Generative AI Basics: What You Need to Know for the AWS AI Practitioner Exam
March 31, 2026

Generative AI is one of the most tested areas in the AWS Certified AI Practitioner exam (AIF-C01). Domain 2, "Generative AI Fundamentals," accounts for 24% of the exam, and Task Statement 2.1 specifically covers the basic concepts. This post breaks down everything you need to understand: what generative AI is, how it works under the hood, the transformer architecture, diffusion models, use cases, and the full project lifecycle.
Where Generative AI Fits
Generative AI is a subset of deep learning. While traditional AI focuses on classifying data or making predictions based on input, generative AI focuses on creating new, original content. That content can span multiple modalities: text, images, audio, video, and code.
At its core, generative AI models learn patterns and representations from large amounts of training data. They then use that learned knowledge to generate outputs that resemble the training data. The models take data or text as input and provide an output, which is essentially a prediction of what the next word or token should be.
Foundation Models
Generative AI relies on foundation models, which are very large and complex neural network models with billions of parameters learned during pre-training. These models are trained on vast amounts of data and look for statistical patterns across modalities like natural language and images.
Three key points about foundation models worth remembering for the exam. First, model size has increased by increasing the number of trainable parameters. Second, more parameters means more memory, which enables more advanced tasks. Third, you can use foundation models as they are or apply fine-tuning techniques to adapt them to specific use cases.
There are publicly available pre-trained foundation models, such as those in Amazon SageMaker JumpStart, which give you a head start without training from scratch.
Key Concepts You Must Know
The exam tests your understanding of several foundational terms. A prompt is the input you send into a generative model. Inference is the process where the prompt is passed into the model to generate an output, and that output is called a completion. The context window is the amount of text or tokens the model can consider at once. Tokens are the units of text the model processes, and the tokenizer is the component that converts human text into those tokens.
Prompt engineering refers to the techniques used to get models to produce better completions. Inference configuration parameters are settings that influence how the model generates its output.
One important strategy is in-context learning: including examples of the desired task inside the prompt. This comes in three flavors. Zero-shot inference provides no examples. One-shot inference provides one example. Few-shot inference provides multiple examples. The more examples you give, the better the model understands what you want.
The Transformer Architecture
The current core element of generative AI is the transformer network, introduced in the 2017 paper "Attention Is All You Need." LLMs like ChatGPT are built on this architecture.
The key innovation is the self-attention mechanism. It helps the model weigh the importance of different parts of the input when generating each output token. This allows the model to capture long-range dependencies and contextual relationships that were difficult to learn with previous architectures like Recurrent Neural Networks (RNNs).
Self-attention works by computing query, key, and value vectors for each input token. The dot products between these vectors determine attention weights, and the output for each token is a weighted sum of the value vectors. This process repeats across multiple layers, building up complex representations.
Transformers also use position embeddings, which encode where each token sits in the sequence. This is crucial for understanding sentence structure and word order, since the architecture does not inherently process tokens in order.
The transformer architecture consists of an encoder and a decoder, each with several layers. It uses residual connections and layer normalization to facilitate training and prevent overfitting.
Model Scaling and Pre-Training
Researchers have found that larger models are more likely to work without additional in-context learning or further training. This has driven the development of increasingly large models, enabled by scalable transformer architecture, access to enormous training data, and more powerful compute resources (especially GPUs).
During pre-training, the model learns from vast amounts of unstructured data, potentially petabytes of text from the internet and curated datasets. This is a self-supervised learning step where model weights get updated to minimize the loss of the training objective.
An important detail for planning: when collecting training data from public sources, you need to process it to increase quality, address bias, and remove harmful content. After this curation step, approximately 1% to 3% of collected tokens are actually used for pre-training.
Unimodal vs. Multimodal Models
Generative AI models can be unimodal or multimodal. Unimodal models work with one data modality. LLMs are a classic example, where both input and output are text. Multimodal models handle multiple modalities like text, images, video, and audio, and they can combine these in ways that enable cross-modal reasoning, translation, search, and creation.
Multimodal use cases include image captioning (generating text from images), visual question answering (answering questions about image content), and text-to-image synthesis using models like DALL-E, Stable Diffusion, and Midjourney.
Diffusion Models
Diffusion models are a class of generative models that learn to reverse a gradual noising process. They support tasks like image generation, upscaling, and inpainting, and they offer a high degree of control over quality and diversity.
For the exam, understand the three main components:
Forward diffusion gradually adds Gaussian noise to the original data until it becomes pure noise.
Reverse diffusion iteratively de-noises the data to reconstruct a coherent output. The model predicts the noise added at each step, conditioned on the partially denoised output from the previous step.
Stable diffusion differs from standard diffusion models by operating in a reduced-definition latent space rather than pixel space, making the process more efficient.
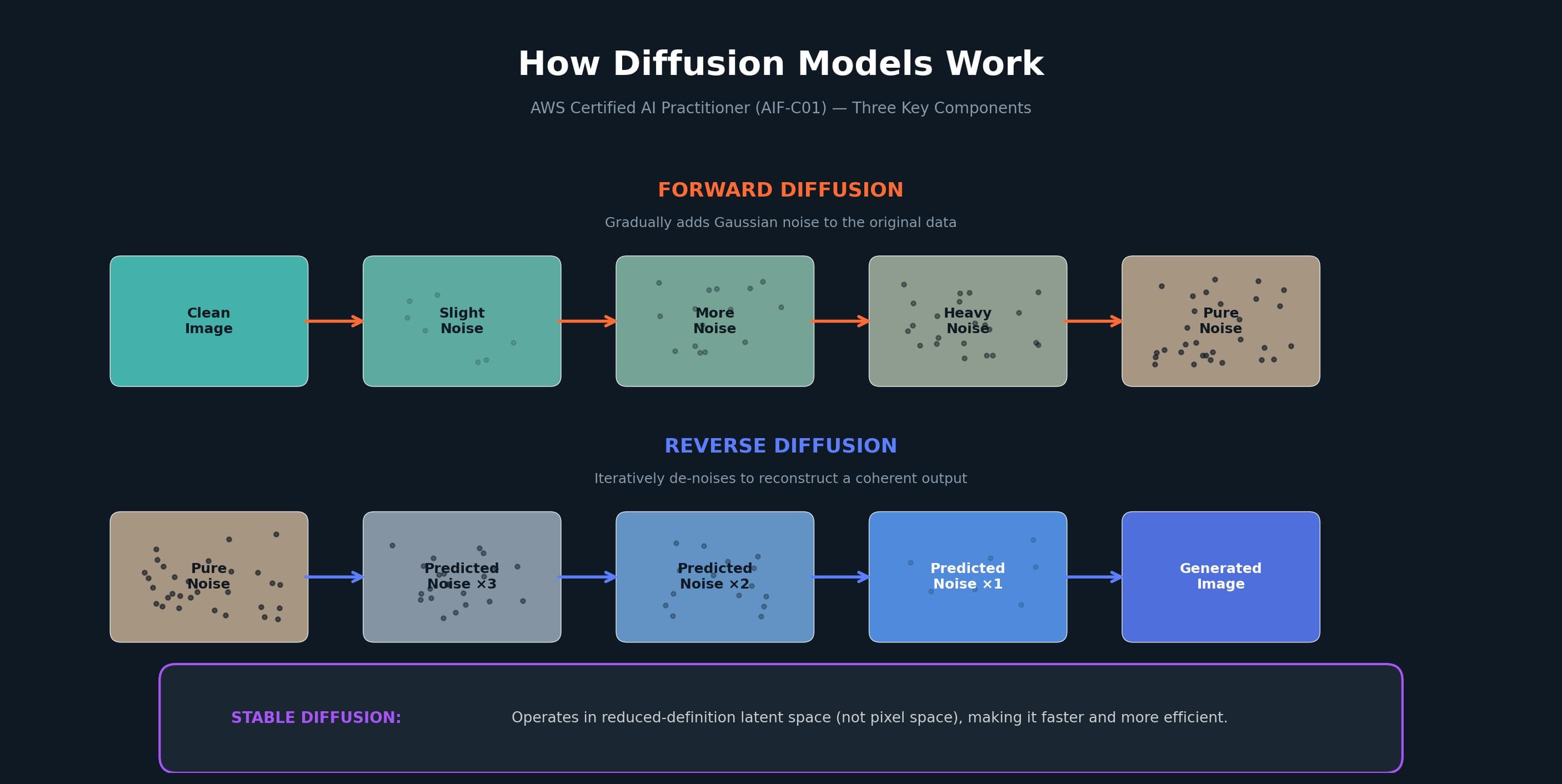
Diffusion models have advantages over Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs): they produce higher quality outputs with more diversity and consistency, and they are more stable and easier to train. Notable examples include Stable Diffusion for images, Whisper for speech recognition, and AudioLM for audio generation.
Generative AI Use Cases and AWS Services
LLMs can be applied to many problem domains without fine-tuning. The main use cases include text generation and rewriting (adapting content for different audiences), text summarization (condensing documents while retaining key ideas), code generation (creating functional code from natural language descriptions), and many others like information extraction, question answering, classification, translation, recommendation engines, and chatbots.
AWS provides several services for building generative AI applications. Amazon Bedrock and Amazon Titan offer pre-trained models for text, image, and audio generation. Amazon SageMaker and Amazon Q Developer (formerly Amazon CodeWhisperer) support code generation and completion. Amazon Sumerian handles virtual production and 3D content creation.
For the exam, remember that three main generative AI architectures exist: GANs, VAEs, and Transformers. Each has unique advantages and limitations, so you should evaluate the objective and dataset before selecting one.
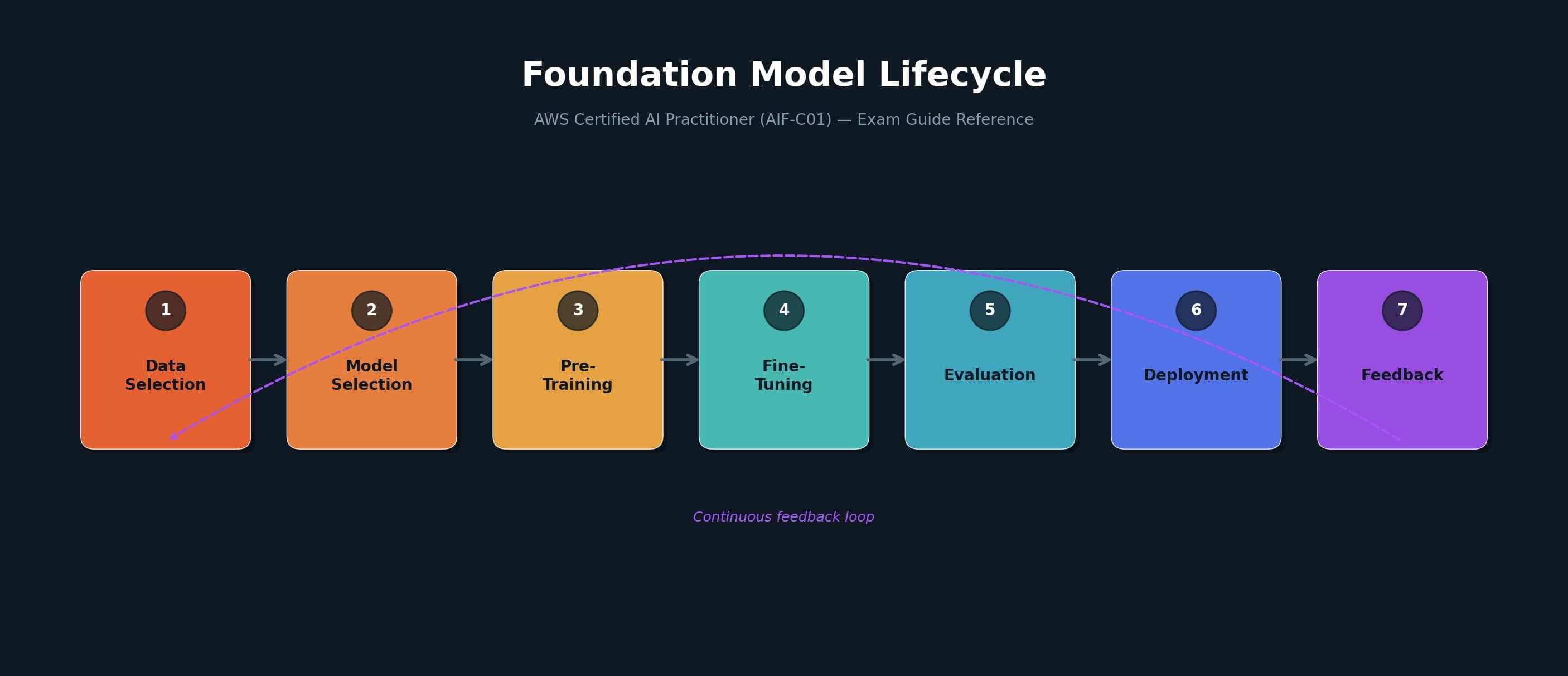
The Generative AI Project Lifecycle
The exam guide defines the foundation model lifecycle with seven stages: data selection, model selection, pre-training, fine-tuning, evaluation, deployment, and feedback. This is a continuous cycle where feedback from deployment loops back to inform future iterations.
When scoping a project, the most important step is defining the scope as narrowly as possible. Ask yourself: does the model need to handle many different tasks, or is it focused on one specific capability? Getting this right saves time and compute costs.
The recommended development approach follows this order. Start with prompt engineering and in-context learning. If the model does not perform well enough, try fine-tuning (a supervised learning process). To ensure the model aligns with human preferences, apply Reinforcement Learning from Human Feedback (RLHF). Throughout the process, evaluate using different metrics and benchmarks, and iterate.
Finally, keep in mind the fundamental limitations of LLMs that are difficult to overcome through training alone: hallucinations (inventing information when the answer is unknown) and limited ability with complex reasoning and mathematics. Additional infrastructure may be needed to address these in production.
References
"Attention Is All You Need" (2017), Vaswani et al. - The original paper introducing the transformer architecture.
AWS Certified AI Practitioner (AIF-C01) Exam Guide - Domain 2: Generative AI Fundamentals.
AWS Skill Builder - Domain 2 Review course for the AIF-C01 exam.