What Generative AI Can and Cannot Do for Your Business
March 31, 2026
Generative AI is having a moment. Every week there is a new model, a new benchmark, a new claim. But behind the noise, the actual question businesses need to answer is simpler: what can this technology reliably do, and where will it fall short?
This post breaks down the capabilities and limitations of generative AI for solving business problems, drawing from the AWS Certified AI Practitioner (AIF-C01) curriculum. Whether you are preparing for the exam or evaluating GenAI for a real project, these are the concepts that matter.
GenAI is a General-Purpose Technology
The most important frame for understanding generative AI is that it is a general-purpose technology, similar to how deep learning was in the last decade. It is not useful for just one application. It applies across many industries and use cases simultaneously.
You are already interacting with AI daily without thinking about it: every web search, every credit card fraud check, every product recommendation on an e-commerce site. Generative AI extends this into new territory because it works in natural language, which makes it accessible to far more people and use cases.
Three core advantages make GenAI attractive for business:
Adaptability. A single model can handle summarization, classification, generation, Q&A, and translation without retraining for each task. Traditional ML models were task-specific; foundation models are not.
Responsiveness. Outputs are in natural language, which means non-technical users can interact with them directly. No specialized interface required.
Simplicity. Before GenAI, building a useful AI application required large labeled datasets, specialized ML expertise, and months of training. GenAI dramatically lowers that barrier. Businesses can now build valuable AI applications at lower cost and faster than before.
The 10-Year-Old Test: A Practical Framework for LLM Task Evaluation
Before building with an LLM, there is a useful mental model for deciding whether it can handle a given task:
Could a 10-year-old child follow the instructions in the prompt and complete the task?
If yes, the LLM can likely do it. If no, the LLM will struggle too.
Consider two examples. First: read an email and determine whether it is a complaint. Most people, including a child, can do this with no extra information. An LLM can too. Second: write a detailed technical article about a brand-new AWS service that was just announced. A child with no information about the service cannot do this. Neither can an LLM. It will produce generic, vague content.
But here is the key insight: if you give that child the press release or the documentation first, they can write something much more specific and accurate. The same is true for an LLM. Providing the right context at inference time is the foundation of Retrieval-Augmented Generation (RAG).
Core Limitations and How to Address Them
GenAI has real constraints. Understanding them is as important as understanding the capabilities.
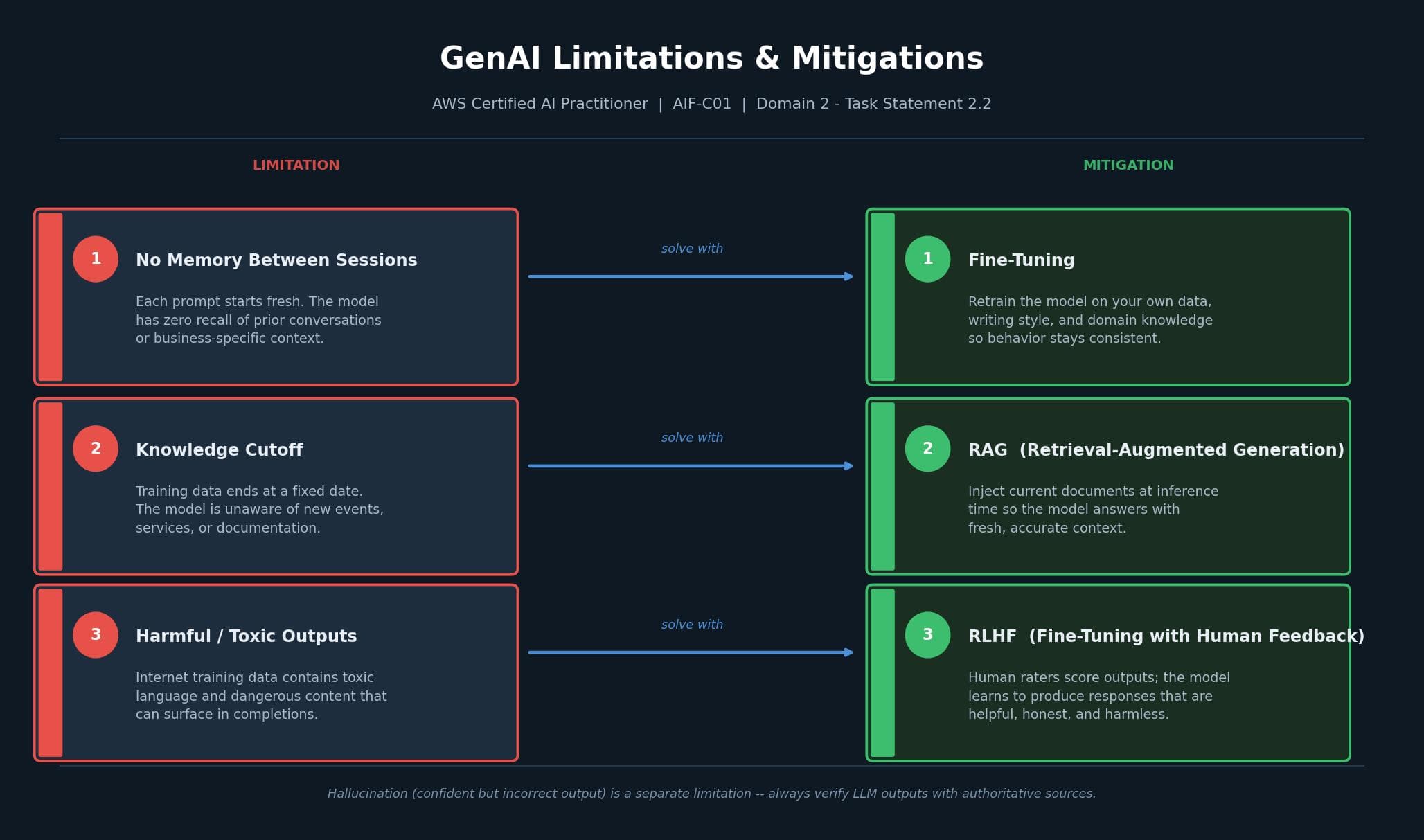
No memory between sessions. LLMs do not remember previous conversations. Each prompt starts fresh. This means you cannot rely on the model accumulating knowledge about your business, your writing style, or your preferences over time through prompting alone. The solution is fine-tuning: training the model on your own data, terminology, and style so that consistent behavior is baked in rather than dependent on context.
Knowledge cutoff. LLMs are trained on data up to a fixed date. They are blind to anything that happened after that cutoff: new product launches, recent events, updated documentation. Without retrieval or tool use, the model cannot access current information. RAG solves this by injecting relevant, up-to-date documents at inference time so the model answers with accurate context.
Harmful and toxic outputs. LLMs are trained on large amounts of internet text. That data includes toxic language, dangerous content, and harmful information. As a result, models can produce offensive completions, aggressive responses, or detailed answers to things they should refuse. This is not an edge case; it is an expected byproduct of how the models are built. Fine-tuning with human feedback (RLHF) is the primary mitigation.
Hallucinations. When an LLM gives a confident but incorrect answer, that is a hallucination. The model does not flag uncertainty. It just states the wrong thing as fact. This is especially dangerous in high-stakes domains like health, law, and finance. The practical rule: always verify LLM outputs against authoritative sources before acting on them.
RLHF and the Three H's Framework
Reinforcement Learning from Human Feedback (RLHF) is the technique used to align models with human values. Human raters score model outputs, and the model learns to produce responses that score better over time. The target alignment goals are captured in the HHH framework:
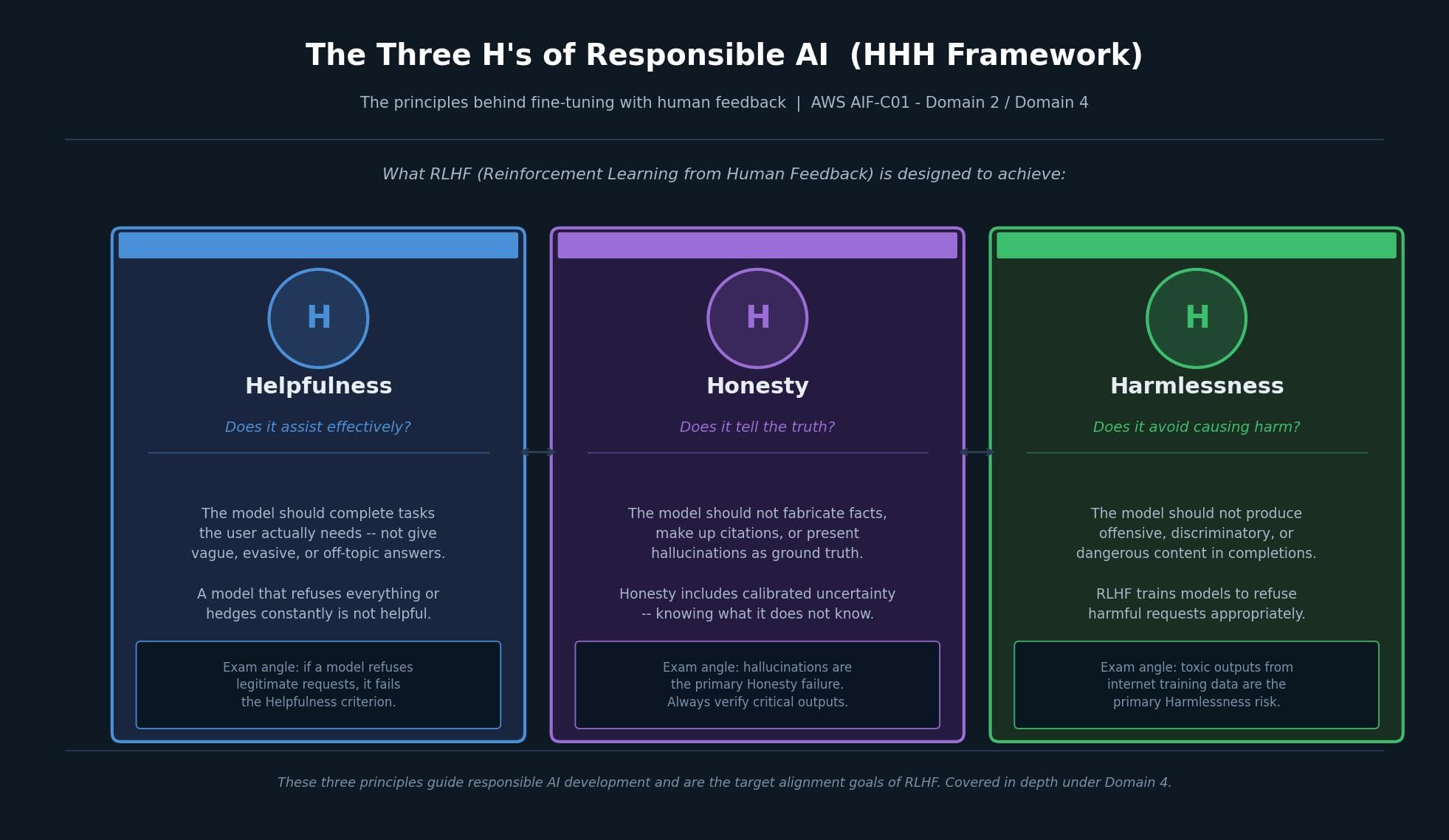
Helpfulness. The model should complete what the user actually needs. A model that refuses everything or constantly hedges is not helpful, even if it is technically safe.
Honesty. The model should not fabricate information or present hallucinations as ground truth. Honesty also includes calibrated uncertainty: knowing what it does not know.
Harmlessness. The model should not produce offensive, discriminatory, or dangerous content. RLHF trains models to recognize and refuse harmful requests appropriately.
These three principles are the responsible AI framework you will encounter throughout the AWS AI Practitioner exam, particularly in Domain 4. They are introduced here because they are also the design goals behind fine-tuning decisions.
Model Interpretability: The Performance vs. Explainability Tradeoff
When selecting a model for a business application, interpretability matters beyond accuracy. High interpretability means you can explain why the model made a given prediction. Low interpretability means you cannot, even if the model is highly accurate.
The tradeoff: simple models are easier to interpret but cannot capture complex non-linear patterns. Neural networks can learn complex patterns but are much harder to explain.
There are two approaches to interpretability analysis. Intrinsic analysis applies to simple models where you can examine the model structure directly to understand its logic. Post hoc analysis applies to complex models like neural networks. It is model-agnostic, meaning it works after training by examining inputs and outputs. Post hoc analysis can operate at a local level (explaining a single prediction) or a global level (understanding overall model behavior).
Evaluating LLM Output: ROUGE and BLEU
Traditional ML models are deterministic: the same input always gives the same output, so accuracy is straightforward to calculate. LLMs are non-deterministic, and their outputs are language-based, which makes evaluation harder.
Two widely used metrics cover the most common evaluation tasks:
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) measures the quality of automatically generated summaries by comparing them to human-written reference summaries. It is recall-focused, measuring how much of the reference was captured by the generated output.
BLEU (Bilingual Evaluation Understudy) measures the quality of machine-translated text by comparing it to human-written translations. It is precision-focused, measuring how much of the generated output appears in the reference.
The short version: ROUGE for summaries, BLEU for translations.
Choosing the Right Foundation Model
Foundation models (FMs) are large models trained on broad, unlabeled datasets. They are the starting point for building AI applications, not the finished product. What distinguishes them from traditional ML models is their scale and breadth: they generalize across many tasks instead of being trained for one specific function.
FMs can generate different content types depending on the architecture: text and chat, images, code, video, and embeddings. For data generation tasks specifically, three model families are widely used. Variational Autoencoders (VAEs) are good for structured data generation and latent space manipulation. Generative Adversarial Networks (GANs) excel at high-quality image synthesis. Autoregressive models like GPT are the standard for text generation and sequential data.
Notable examples: Stable Diffusion by Stability AI is the dominant image generation FM; GPT-4 from OpenAI powers ChatGPT for natural language tasks.
Measuring Business Value: The Right KPIs for GenAI
For GenAI to justify its cost, you need the right metrics. The AWS exam expects you to know these categories:
Output quality metrics measure whether the model produces trustworthy outputs: relevance (is it on-topic?), accuracy (is it correct?), coherence (does it make sense?), and appropriateness (is it safe for the context?).
Efficiency metrics measure operational impact: task completion rates, reduction in manual effort, and error rate. Lower error rate maintains both accuracy and credibility.
Business performance metrics connect AI to outcomes: conversion rate, average revenue per user (ARPU), customer lifetime value (CLTV), and cross-domain performance.
One important note on deployment: getting real value from FMs is not just a model problem. Organizations also need to handle integration with existing systems like ERP and CRM, build the technical talent to maintain the model, and invest in the computational infrastructure to run it cost-effectively.
Finally, AI is not a set-and-forget system. Models drift as data patterns change and business requirements evolve. Continuous monitoring, review, and re-evaluation are required to keep the system meeting its goals.
Key Takeaways
Generative AI is powerful, but it works best when you understand its edges. The advantages are real: adaptability across tasks, natural language output, and lower cost to build. The limitations are also real: no memory, a knowledge cutoff, potential for harmful outputs, and hallucinations. Each limitation has a known solution (fine-tuning, RAG, RLHF), and knowing which solution fits which problem is what the AIF-C01 exam tests.
For practitioners, the HHH framework (Helpfulness, Honesty, Harmlessness) is the clearest articulation of what responsible GenAI deployment looks like. And when it comes to measuring success, output quality and business KPIs need to be tracked together, not separately.
This post is part of a study series for the AWS Certified AI Practitioner exam (AIF-C01). It covers Domain 2, Task Statement 2.2: Capabilities and Limitations of Generative AI for Solving Business Problems.