Foundation Models on AWS: Design Considerations, RAG, and Agents Explained
April 01, 2026

Building applications on top of foundation models (FMs) is not just about picking a model and writing a prompt. There are real architectural decisions that directly affect cost, performance, and maintainability. This post covers the key design considerations for FM-based applications on AWS: model selection, RAG, inference parameters, and Agents for Amazon Bedrock. It maps to Domain 3 of the AWS AI Practitioner exam (AIF-C01), worth 28% of the exam.
How to Pick the Right Pre-Trained Model
There is no universally "best" model. The right choice depends on your requirements across several dimensions.
Cost is usually the first filter. Training or fine-tuning a large model costs real money in compute, storage, and time. A model that is 98% accurate might cost hundreds of thousands of dollars to train, while a 97% accurate alternative might cost a fraction of that. If the accuracy gap does not matter for your use case, the cheaper option wins. Cost compounds across the full lifecycle: training, inference, storage, and ongoing maintenance.
Latency is a hard constraint for real-time applications. Some complex models have inference times that cannot meet a real-time SLA. The classic example: a self-driving vehicle cannot wait for a slow model. K-Nearest Neighbors (KNN) does most of its computation at inference time and degrades as data grows, making it a poor fit for high-dimensional, low-latency scenarios regardless of offline accuracy.
Modality determines what kind of data the model can process. Text, image, and audio each require their own embeddings. If your application handles multiple modalities, you may need an ensemble approach, combining specialized models rather than relying on a single generalist.
Architecture matters because different neural network designs have different strengths. Convolutional Neural Networks (CNNs) excel at image recognition. Recurrent Neural Networks (RNNs) are better suited for sequential text processing. The number of parameters, layers, and operations directly affects speed, memory usage, and accuracy.
Metrics define what "good" means. Before selecting a model, decide which metrics reflect your actual use case:
Accuracy: fine for balanced datasets, misleading for imbalanced ones
Precision / Recall / F1: better for classification with class imbalance
RMSE / MAE: for regression tasks
MAP (Mean Average Precision): for object detection and ranking
For object detection, MAP tells you more than accuracy does. It measures how well the model locates and classifies multiple objects in an image, not just whether a single prediction was correct.
Interpretability vs. Explainability
This distinction is frequently tested and often confused.
Interpretability means you can explain mathematically, through coefficients and formulas, exactly why a model produced a given output. This is only feasible with simple models like linear regression or decision trees. Foundation models are not interpretable by design. They are black boxes.
Explainability is different. It does not open the black box. Instead, it approximates the model's behavior in a specific region using a simpler, interpretable model. It reverse-engineers the output locally without exposing the full internal mechanics.
The practical implication: if interpretability is required (regulatory compliance, healthcare, financial decisions), foundation models may be the wrong tool. A simpler, auditable model may serve you better. More complex models improve performance but make outputs harder to explain and more expensive to operate.
Inference Parameters: Controlling What the FM Returns
Inference is the process of sending a prompt to a model and receiving an output. Amazon Bedrock lets you tune a set of inference parameters to shape that output without changing the model itself.
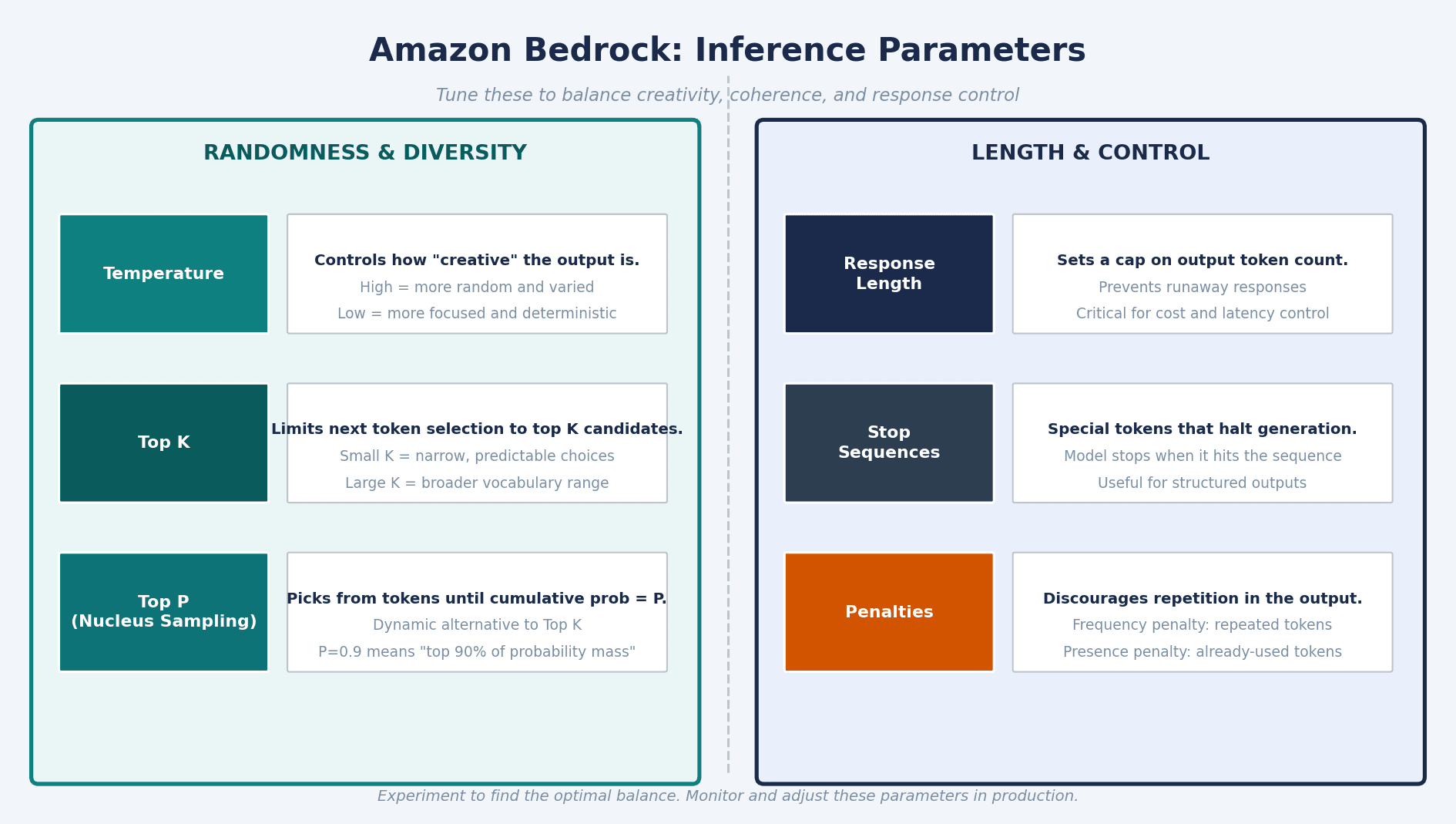
Parameters split into two groups:
Randomness and diversity:
Temperature: controls creativity. Higher values produce more varied, less predictable outputs. Lower values produce more focused, deterministic responses. Use low temperature when you need consistent, factual outputs.
Top K: limits next token selection to the top K candidates. Smaller K means narrower, more predictable word choices.
Top P (Nucleus Sampling): picks from tokens until their cumulative probability reaches P. A dynamic version of Top K that adapts to the shape of the probability distribution.
Length and control:
Response Length: caps how many tokens the model generates. Critical for cost and latency control.
Stop Sequences: tokens that signal the model to stop generating. Useful when you need structured, bounded outputs.
Penalties: discourage repetition. Frequency penalty targets tokens the model has repeated; presence penalty targets any token already used in the response.
The right combination depends on your use case. A support bot benefits from low temperature and strict response length. A creative assistant can afford higher temperature and looser constraints. Experiment, find a balance, then monitor in production.
Vector Databases: The Factual Reference Layer
A vector database stores data as mathematical representations called embeddings. Embeddings are numerical representations of text, images, or other data that capture meaning and relationships between concepts.
An embedding model is a prerequisite. You feed data through it, it produces dense vectors, and those vectors populate the database. The database enables fast similarity search: given a query vector, find the most similar stored vectors.
Vector databases serve as the factual reference layer for FM-based applications. They give models access to domain-specific, up-to-date knowledge that was not part of their training data. On AWS, your main options are:
Amazon OpenSearch Service: the most feature-rich option for vector search. Supports semantic search, RAG pipelines, recommendation engines, and media search. Plugins add alerting, observability, fine-grained access control, and security monitoring. OpenSearch Serverless offers a dedicated vector engine that handles the infrastructure.
Amazon Aurora and Amazon RDS for PostgreSQL (with the
pgvectorextension): relational options with vector support.Amazon DocumentDB (MongoDB compatibility): document store with vector capabilities.
Amazon Neptune: graph database with vector support.
Redis: in-memory option for low-latency vector lookup.
Semantic search via OpenSearch can use embedding models like BERT (hosted on Amazon SageMaker) to move beyond keyword matching and retrieve results based on meaning.
RAG: Grounding FM Responses in External Knowledge
Retrieval Augmented Generation (RAG) is the most practical pattern for FM applications that need current or proprietary information without retraining the model.
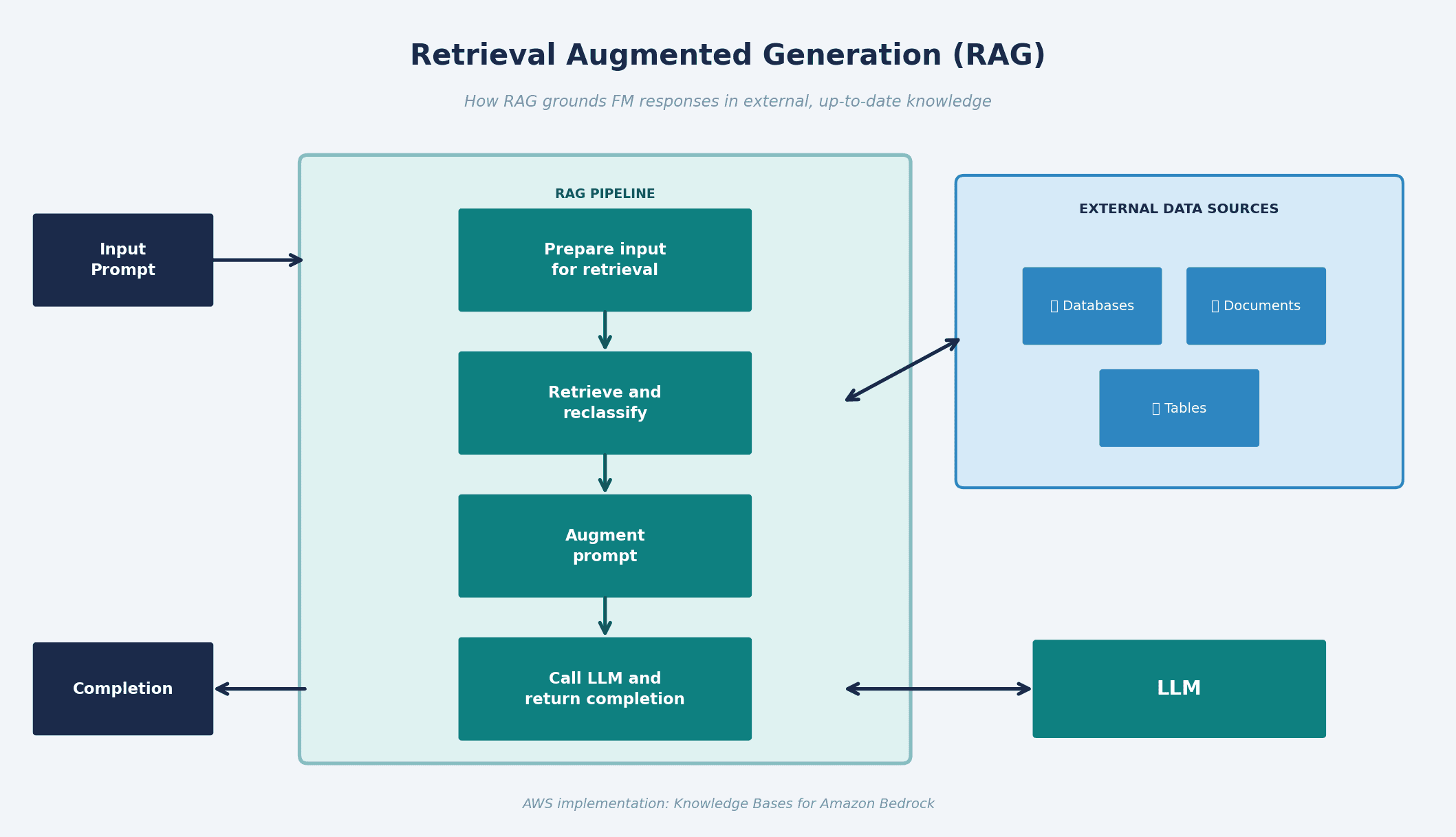
The flow has four steps:
Prepare input for retrieval: the incoming prompt is converted into a vector embedding.
Retrieve and reclassify: that embedding is matched against the vector database to find the most similar stored vectors.
Augment prompt: the retrieved content is appended to the original prompt, giving the model relevant context.
Call LLM and return completion: the augmented prompt is sent to the model, which generates a grounded response.
RAG solves hallucinations by giving the model access to verifiable, current data at inference time. Instead of relying solely on training knowledge (which has a cutoff), the model pulls fresh context on each query.
AWS implementation: Knowledge Bases for Amazon Bedrock handles this end-to-end. You connect your data sources, they are stored as embeddings in a vector store, and the FM retrieves relevant context automatically on each request. No retraining required.
RAG is particularly strong for question-answering, customer support, and any use case where the model needs access to internal docs, product catalogs, or frequently changing data.
Agents for Amazon Bedrock: From Understanding to Acting
A foundation model is good at understanding and generating text. But it cannot book a flight, update a database, or trigger a business workflow on its own. Those tasks require organization-specific logic and external integrations.
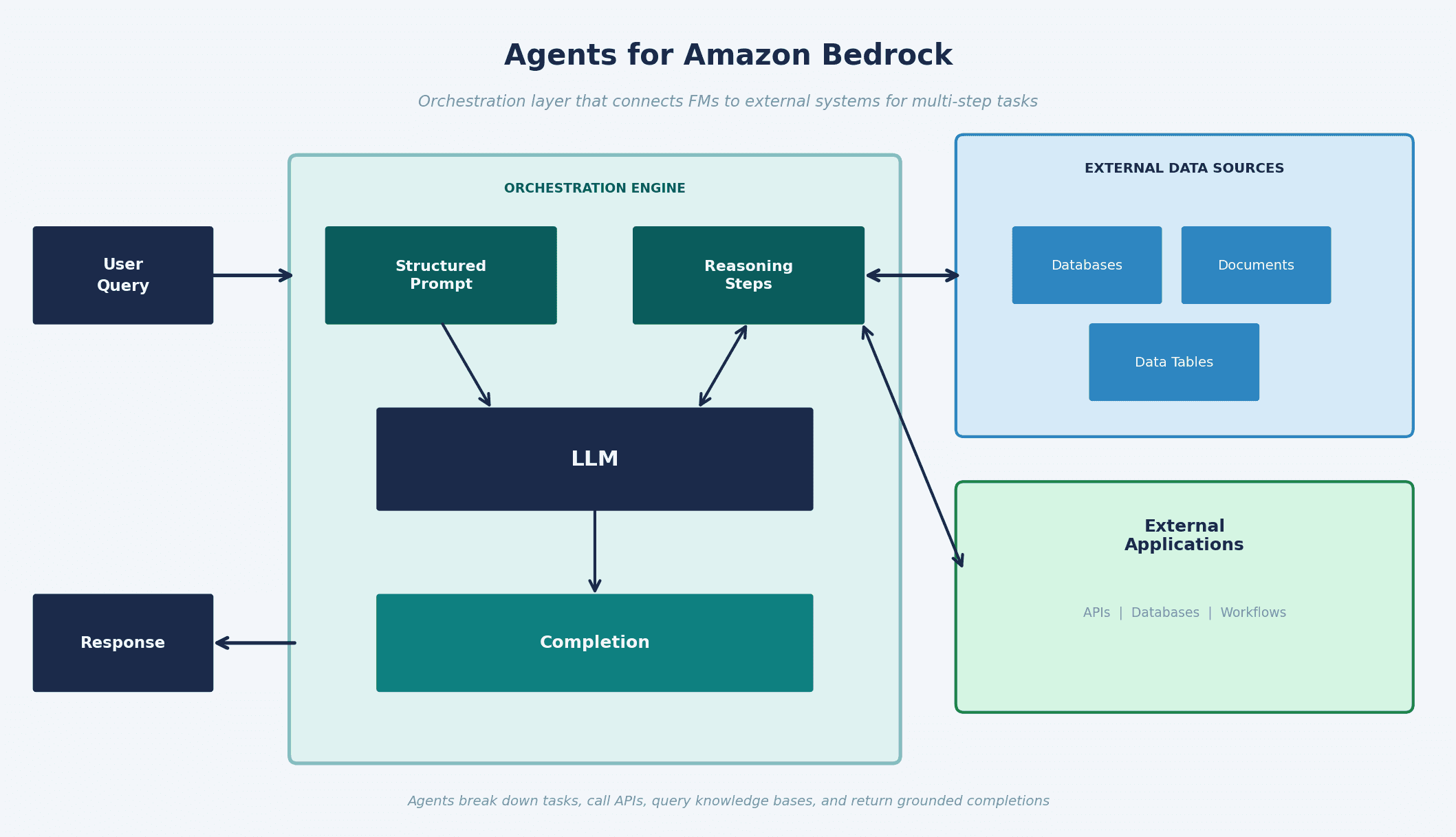
Agents for Amazon Bedrock solve this. They act as an orchestration layer between the user, the FM, and external systems. An agent can:
Break down a complex multi-step task automatically
Generate orchestration logic or write custom code to handle individual steps
Connect securely to databases and services via APIs
Invoke knowledge bases when additional context is needed
Return a grounded completion back to the user
The internal loop: the agent takes the user query, builds a structured prompt, uses reasoning steps that it updates as it calls external systems, passes everything to the LLM, and produces a completion. It can iterate through multiple reasoning steps before returning a final answer.
Example: a travel booking agent. The user says "book me a scuba diving trip for next month." The agent checks availability via API, reads pricing from a knowledge base, confirms with the user, and triggers the booking workflow. The FM handles the conversation; the agent handles execution.
Choosing the Right Customization Approach
One of the most tested concepts in Domain 3 is knowing when to use each FM customization method and what it costs.
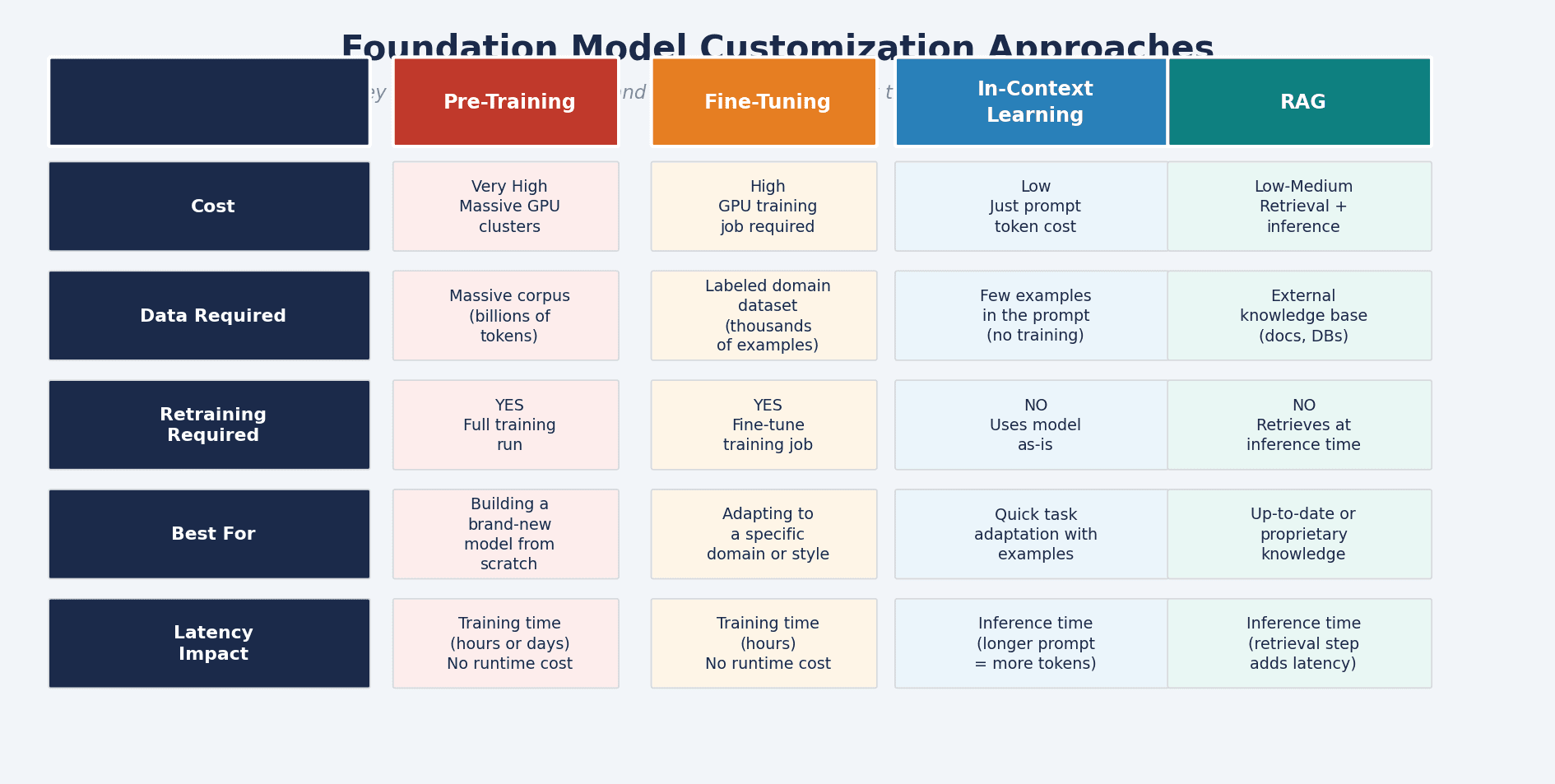
Pre-Training: building a model from scratch on a massive corpus. Requires enormous compute and data. Only justified if you are building a new foundation model from the ground up.
Fine-Tuning: adapting a pre-trained model to a specific domain using a labeled dataset. Requires a training job. The model learns permanently, making it well-suited for domain-specific language, tone, or task behavior. Higher cost than RAG, but results persist across all future requests.
In-Context Learning: providing examples and instructions directly in the prompt at inference time. No training required. Fast and cheap, but limited by context window size and does not persist knowledge between sessions.
RAG: injecting external knowledge at inference time via a vector database. No retraining. Cost scales with retrieval and inference, not training. Best choice when you need current data, proprietary information, or want to reduce hallucinations without committing to a training job.
For most production applications on AWS, RAG is the starting point. Fine-tuning becomes worth it when you need persistent behavior changes that prompt engineering and retrieval cannot achieve.
Key Takeaways
Model selection is a tradeoff across cost, latency, modality, complexity, and interpretability. Define your constraints before picking.
Foundation models are black boxes. If interpretability is required, use simpler models.
Inference parameters control creativity and response length without touching the model. Monitor them in production.
Vector databases are the factual reference layer. An embedding model is a prerequisite.
RAG grounds outputs in external knowledge at inference time. No retraining needed.
Agents for Amazon Bedrock extend FMs to take real-world actions via APIs and external workflows.
Customization cost hierarchy: pre-training > fine-tuning > RAG > in-context learning.
This post covers Task Statement 3.1 from Domain 3 of the AWS AI Practitioner exam (AIF-C01), which focuses on Foundation Models and carries 28% of the exam weight.