AWS Generative AI Infrastructure: What You Need to Know for the AIF-C01 Exam
March 31, 2026

If you are studying for the AWS AI Practitioner (AIF-C01) certification, Task Statement 2.3 from Domain 2 is one you want to understand well. It covers how AWS infrastructure supports generative AI applications, from the hardware running your models to the managed services that let you skip training entirely.
This post breaks down the key concepts: the three-layer generative AI stack, AWS services for building gen AI apps, pricing models, and the security fundamentals that protect AI systems at every level.
Why AWS for Generative AI?
AWS pitches several advantages for building generative AI applications on their platform: accessibility to models and tools, a lower barrier to entry through managed services, cost-effectiveness with specialized hardware, and speed to market with pre-built solutions.
The practical takeaway is that most organizations will not train their own large language models. Training requires massive investment in research, data collection, cleaning, compute, and time. AWS provides the infrastructure and services so you can skip straight to fine-tuning or using pre-trained models.
Transfer Learning: Build on What Already Exists
Transfer learning is the process of taking a pre-trained model and fine-tuning it on your own dataset, without training from scratch. The model already understands general patterns from its original training data. Your job is to teach it how those patterns map to your specific use case.
This approach produces accurate models with smaller datasets and less training time. You can source pre-trained models from the internet or build your own. Amazon SageMaker JumpStart accelerates this by providing a model hub with pre-built projects, datasets, algorithms, and solutions based on industry best practices.
The Three Layers of the AWS Generative AI Stack
AWS organizes its generative AI offerings into three layers, and security applies at every single one.
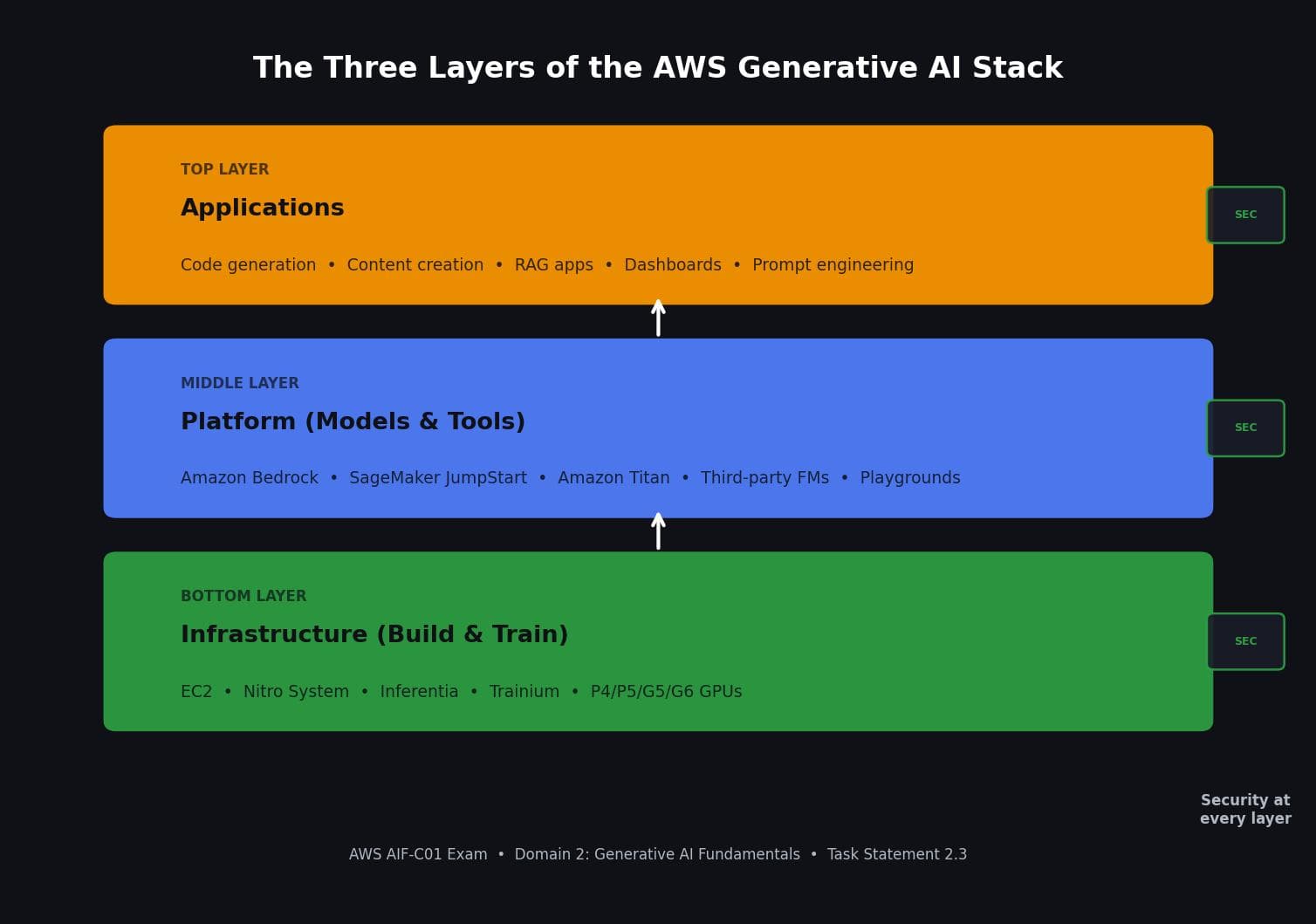
Bottom Layer: Infrastructure (Build and Train). This is where the hardware lives. AI workloads demand serious compute for both training and inference. AWS offers specialized chips like Inferentia (optimized for inference) and Trainium (optimized for training), along with GPU instances like P4, P5, G5, and G6. The AWS Nitro System provides hardware-level security, ensuring zero unauthorized access to your model weights and processed data across all Nitro-based EC2 instances.
Middle Layer: Platform (Models and Tools). This layer gives you access to foundation models and the tools to build applications around them. Services like Amazon Bedrock and SageMaker JumpStart live here. You can train, tune, and deploy models without managing the infrastructure yourself.
Top Layer: Applications. This is where generative AI meets users. Applications in this layer write code, generate content, derive insights, and take actions. Examples include dashboards, prompt engineering interfaces, and specific architectures like Retrieval-Augmented Generation (RAG).
Key AWS Services for Building Gen AI Applications
Amazon SageMaker JumpStart is a model hub. It helps you quickly deploy foundation models and integrate them into your applications. It supports fine-tuning and provides resources like blogs, videos, and example notebooks. Important cost note: JumpStart models require GPUs, so check the SageMaker pricing page before selecting compute, and always delete model endpoints when not in use.
Amazon Bedrock is a managed service that gives you API access to multiple foundation models, both AWS models and third-party ones from providers like Cohere and Stability AI. You can import custom model weights and serve them on-demand. The pricing is straightforward: pay only for what you use, no time-based commitments.
Amazon Titan is Amazon's own foundation model, optimized for text generation. Since many foundation models overlap in text generation capabilities, Bedrock provides Playgrounds where you can run inference against different models to find the best fit for your use case. You can adjust inference parameters and compare completion results.
PartyRock is a playground built on Bedrock designed for learning. You can build simple generative AI applications (playlists, trivia games, recipes) to understand how foundation models respond to different prompts.
Pricing Models: Host vs. Pay-by-Token
Two main options for using LLMs:
Self-hosted: You pay for the compute resources to run the model, plus potentially a license fee for the LLM itself. This requires infrastructure investment and ongoing maintenance.
Token-based pricing: You pay based on the number of tokens processed. A token is a discrete unit of information, such as a word or character in text, or a pixel in an image. Both input and output tokens are counted. This model adds scalability without infrastructure investment, and it is the approach most teams take through services like Amazon Bedrock.
AI System Security: The Exam Cares About This
Every AI system has three critical components: input, model, and output. Each one is a potential attack surface.
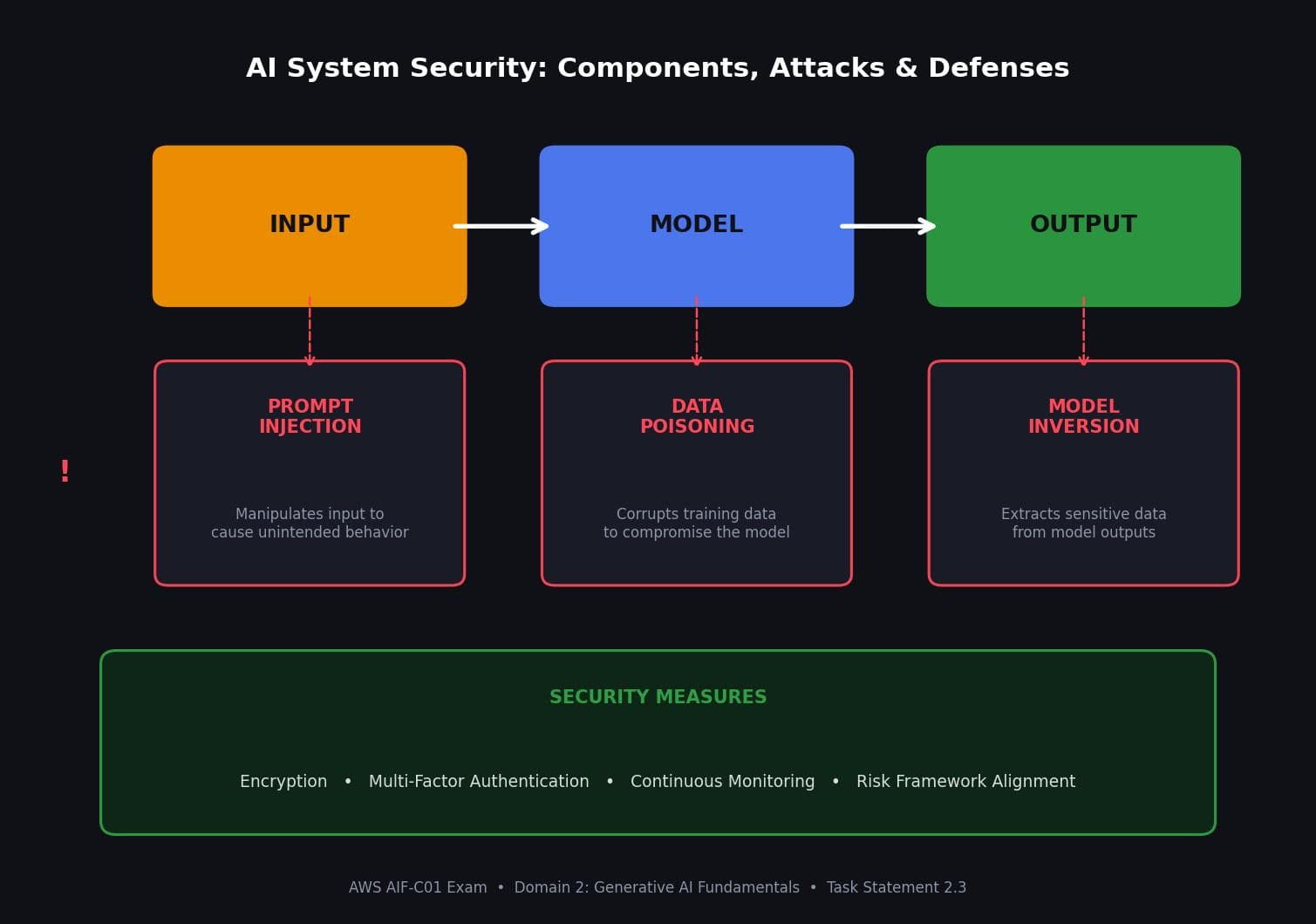
Prompt injection targets the input. An attacker manipulates what goes into the model to cause unintended behavior.
Data poisoning targets the model. By corrupting training data, an attacker compromises the model's behavior at the source.
Model inversion targets the output. An attacker uses the model's responses to extract sensitive information from the training data.
The consequences of these attacks include privacy breaches, data manipulation, abuse, and compromised decision-making. AWS recommends mitigating these risks with encryption, multi-factor authentication, continuous monitoring, and alignment to your organization's risk tolerance and governance frameworks.
The AWS ML Stack and Global Infrastructure
The AWS ML stack builds on top of the AWS Global Infrastructure (Regions, Availability Zones, edge locations). Many AWS managed services have high availability built in. On top of that infrastructure sit the ML services (like SageMaker), and on top of those sit the AI services: pre-built algorithms and models you can integrate directly into your applications via APIs and the AWS SDK, without needing ML expertise.
The AWS Cloud Adoption Framework for AI, ML, and Generative AI (CAF-AI) serves as a starting point and guide for organizations adopting these technologies. It is a useful resource for AI strategy discussions with your team and AWS Partners.
Quick Reference for the Exam
The AIF-C01 will test you on the three layers of the generative AI stack, what lives at each layer, and what security means across them. Know the difference between SageMaker JumpStart (model hub, requires GPUs) and Amazon Bedrock (managed API access, pay per use). Understand token-based pricing and why it adds scalability. Be able to name the three AI-specific vulnerabilities (prompt injection, data poisoning, model inversion) and map each one to the component it attacks: input, model, and output respectively. Remember that the Nitro System provides hardware-level security for all Nitro-based instances, including ML accelerator chips.