AI, ML, Deep Learning, and Generative AI: The Complete Breakdown for the AWS AI Practitioner Exam
March 30, 2026

Task Statement 1.1 of the AWS AI Practitioner exam (AIF-C01) covers the foundational layer: what AI actually is, how machine learning works under the hood, the different types of training data, how models get deployed, and how deep learning led to the generative AI era. This post breaks down every concept you need to know, with the AWS services that connect to each one.
The AI Hierarchy: AI, ML, Deep Learning, and Generative AI
Before anything else, you need to understand how these four terms relate to each other. They are not synonyms. They are nested layers, where each one is a subset of the one above it.
Artificial Intelligence (AI) is the broadest layer: a field of computer science dedicated to solving cognitive problems associated with human intelligence, like learning, creation, and image recognition.
Machine Learning (ML) is a branch of AI that uses data and algorithms to imitate the way humans learn, gradually improving accuracy. Models are trained on large datasets to identify patterns and make predictions.
Deep Learning is a type of ML inspired by the human brain. It uses layers of neural networks to process information and can recognize speech and identify objects in images.
Generative AI sits at the core. It uses deep learning models pre-trained on massive datasets to generate original content: text, images, videos, music, and code. It starts with a prompt and produces a response using transformer neural networks.
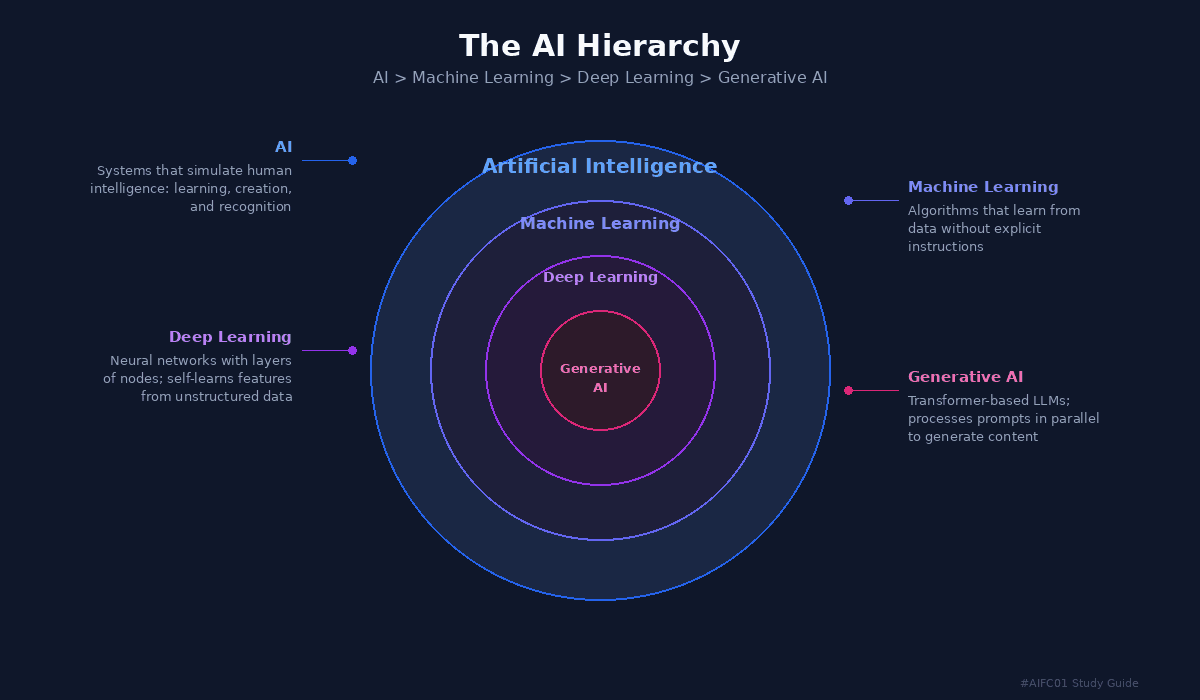
The AI Hierarchy diagram showing concentric circles: AI > Machine Learning > Deep Learning > Generative AI
Key AI Concepts and Terminology
The exam tests your understanding of these core concepts. Each one represents a different capability of AI systems.
Inferences are predictions made by AI models. An inference is an educated guess where the model gives a probabilistic result, not a definitive answer.
Anomaly Detection lets AI detect deviations from expected patterns, like an unusual drop in customer service calls when a system goes offline.
Computer Vision processes images and video for object identification, facial recognition, classification, and monitoring. Example: detecting scratches on a manufactured surface.
Natural Language Processing (NLP) allows machines to understand, interpret, and generate human language naturally. It powers voice assistants like Alexa and customer service chatbots.
Language Translation goes beyond word-to-word replacement. AI analyzes how words influence each other to communicate accurate meaning across languages, enabling real-time translation.
Regression Analysis processes historical time series data to predict future values, like forecasting daily customer counts to determine staffing needs.
Generative AI can hold intelligent conversations and generate original content. Using Amazon Bedrock, a single prompt can produce complete creative output like song lyrics or articles.
How Machine Learning Models Are Trained
Understanding the training process is fundamental. It follows four steps:
The algorithm is given known data consisting of features (columns in a table, or pixels in an image).
The algorithm finds the correlation between input data features and the known expected output.
Internal parameter values are adjusted iteratively until the model reliably produces the expected output.
Once trained, the model can make accurate predictions from new, unseen data. This is called inference.
Types of Training Data and AWS Services
The exam expects you to know four types of training data, the AWS services associated with each, and why Amazon S3 is the central training data store.
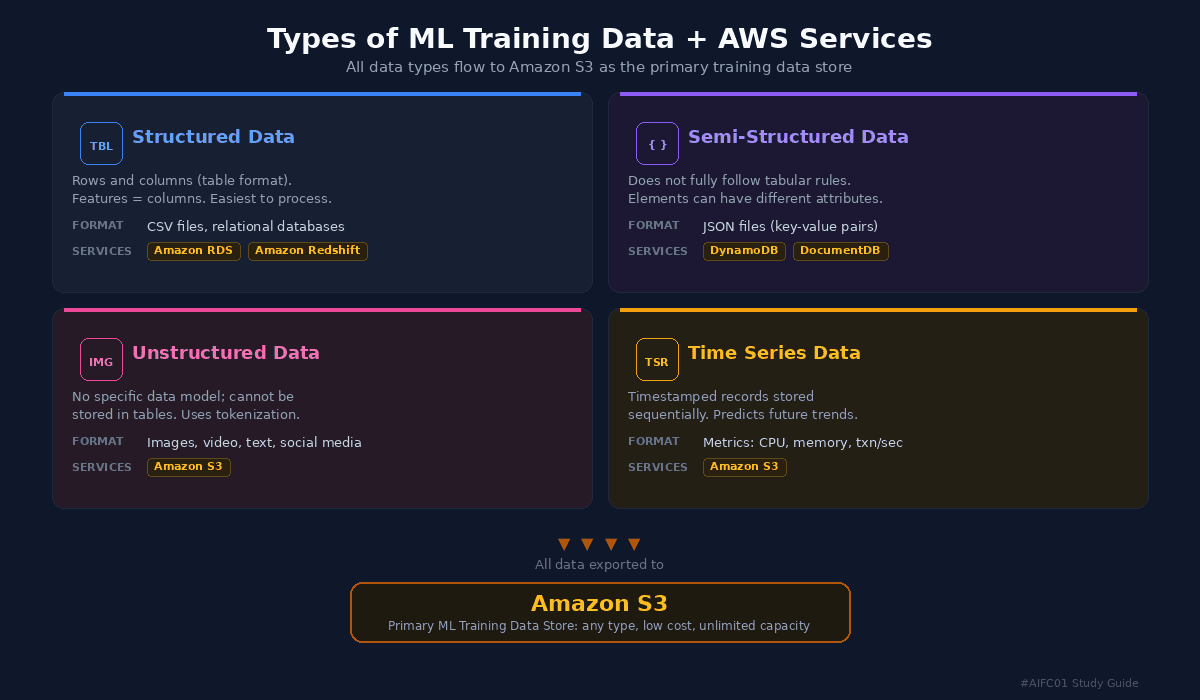
Types of ML Training Data + AWS Services infographic showing four data types flowing to Amazon S3
Structured Data is the easiest to understand and process. It is stored as rows and columns in table format, where features equal columns. Examples include CSV files and relational databases. AWS services for structured data include Amazon Relational Database Service (Amazon RDS) and Amazon Redshift, both queryable via SQL. For model training, data is exported to Amazon S3.
Semi-Structured Data does not fully follow tabular rules. Data elements can have different or missing attributes. The typical example is JSON files where features are represented as key-value pairs. AWS services include Amazon DynamoDB and Amazon DocumentDB (with MongoDB compatibility). For training, data is exported to Amazon S3.
Unstructured Data does not conform to any specific data model and cannot be stored in table format. Examples include images, video, text files, and social media posts. Features are derived using processing techniques like tokenization, which breaks text into individual words or phrases. The primary AWS service is Amazon Simple Storage Service (Amazon S3).
Time Series Data consists of records labeled with timestamps and stored sequentially. It is used for training models that predict future trends. A practical example: microservice performance metrics like memory usage, CPU percentage, and transactions per second. A model can discover patterns in this data and proactively scale infrastructure before expected load increases. Stored in Amazon S3 for training.
Amazon S3 is the primary source for ML training data because it can store any type of data, offers lower cost than alternatives, and provides virtually unlimited storage capacity.
Model Artifacts and Deployment
The training process produces model artifacts: trained parameters, a model definition that describes how to compute inferences, and other metadata. These artifacts are stored in Amazon S3 and packaged with inference code (the software that implements the model) to create a deployable model.
Real-Time vs. Batch Inference
Once a model is deployed, there are two ways to run inference:
Real-Time Inference keeps an endpoint always available to accept requests. Ideal for low latency, high throughput scenarios. Some compute resources are always running.
Batch Inference is for offline processing when large amounts of data are available upfront. No persistent endpoint needed, making it more cost-effective when waiting for results is acceptable. Resources only run during processing. Example: monthly sales data processing to forecast inventory needs.
The Three Machine Learning Styles
The exam tests your knowledge of three categories of learning algorithms. Knowing the differences is critical.
Supervised Learning trains models on pre-labeled data where both input and desired output are specified. For example, showing a model pictures labeled "fish" and "not fish" for image classification. The challenge is that it requires large amounts of labeled data, which involves significant human effort. AWS provides Amazon SageMaker Ground Truth for labeling, which integrates with Amazon Mechanical Turk, a crowdsourcing service for affordable, globally distributed data labeling.
Unsupervised Learning trains on data that has features but no labels. It can spot patterns, group data into clusters, and split data into groups. Use cases include pattern recognition, anomaly detection, and automatic data categorization. Setup is straightforward since no labeling is required. Example: detecting a failing temperature sensor at an oil well when its data falls outside the normal range.
Reinforcement Learning focuses on autonomous decision making by an agent within an environment. The agent takes actions to achieve specific goals and learns through trial and error. No labeled input is required. Actions that move the agent closer to the goal are rewarded. AWS teaches this concept through AWS DeepRacer, a model race car where the agent (car) learns to stay on the track (environment) and finish as efficiently as possible.
A key distinction for the exam: both unsupervised and reinforcement learning use unlabeled data, but reinforcement learning has a predetermined end goal while unsupervised learning does not.
Model Quality Problems: Overfitting, Underfitting, and Bias
Three critical issues can affect model quality, and the exam will test you on all three.
Overfitting occurs when a model performs well on training data but poorly on new, unseen data. The model fits the training data too closely and fails to generalize. It can also happen when a model is trained for too long and starts to overemphasize unimportant features called noise. The fix: train with more diverse data.
Underfitting occurs when the model cannot determine a meaningful relationship between input and output data. It gives inaccurate results on both training data and new data. Common causes: not trained long enough, or trained with a dataset that is too small. Data scientists look for the sweet spot in training time.
Bias occurs when there are disparities in model performance across different groups. Results are skewed in favor of or against an outcome for a particular class. The root cause is training data that lacks diversity. For example, a loan application model trained on data with no approved applications from 25-year-old women in Wisconsin may learn to reject that group, even when their qualifications would normally lead to approval. Bias must be addressed proactively through data inspection before training, and deployed models require ongoing fairness evaluation.
Deep Learning: Neural Networks in Detail
Deep learning uses algorithmic structures called neural networks, based on the structure of the human brain. Software modules called nodes simulate the behavior of neurons. A neural network comprises an input layer, several hidden layers, and an output layer. Every node assigns weights to each feature, and during training, weights are repeatedly adjusted to minimize the error between predicted and actual output.
Neural networks have existed for decades, but the required computing power was not viable until low-cost cloud computing arrived.
Traditional ML vs. Deep Learning: Traditional ML works best with structured and labeled data, requires manual feature selection, and costs less. Deep learning excels with unstructured data (images, video, text), self-learns its features, but costs significantly more in infrastructure. Deep learning's key advantage for computer vision is that it does not need features given to it; it can identify patterns and extract features on its own. The tradeoff: it may need millions of images to train accurately.
Generative AI and Large Language Models
Generative AI is accomplished using deep learning models pre-trained on extremely large datasets. The key innovation is the transformer neural network, which converts an input sequence (the prompt) into an output sequence (the response). Unlike standard neural networks that process sequences one word at a time, transformers process sequences in parallel, which speeds up training and allows much bigger datasets.
Large Language Models (LLMs) contain billions of features, capturing a wide range of human knowledge. They can understand human language, summarize long articles, generate text, translate languages, write creative content, and even write computer programming languages. To try Amazon Bedrock for free, visit partyrock.aws.